Today, we are releasing a plugin that allows customers to use the Titan graph engine with Amazon DynamoDB as the backend storage layer. It opens up the possibility to enjoy the value that graph databases bring to relationship-centric use cases, without worrying about managing the underlying storage.
The importance of relationships
Relationships are a fundamental aspect of both the physical and virtual worlds. Modern applications need to quickly navigate connections in the physical world of people, cities, and public transit stations as well as the virtual world of search terms, social posts, and genetic code, for example. Developers need efficient methods to store, traverse, and query these relationships.
Social media apps navigate relationships between friends, photos, videos, pages, and followers. In supply chain management, connections between airports, warehouses, and retail aisles are critical for cost and time optimization. Similarly, relationships are essential in many other use cases such as financial modeling, risk analysis, genome research, search, gaming, and others. Traditionally, these connections have been stored in relational databases, with each object type requiring its own table. When using relational databases, traversing relationships requires expensive table JOIN operations, causing significantly increased latency as table size and query complexity grow.
Enter graph databases
Graph databases belong to the NoSQL family, and are optimized for storing and traversing relationships. A graph consists of vertices, edges, and associated properties. Each vertex contains a list of properties and edges, which represent the relationships to other vertices. This structure is optimized for fast relationship query and traversal, without requiring expensive table JOIN operations.
In this way, graphs can scale to billions of vertices and edges, while allowing efficient queries and traversal of any subset of the graph with consistent low latency that doesn’t grow proportionally to the overall graph size. This is an important benefit for many use cases that involve accessing and traversing small subsets of a large graph. A concrete example is generating a product recommendation based on purchase interests of a user’s friends, where the relevant social connections are a small subset of the total network. Another example is for tracking inventory in a vast logistics system, where only a subset of its locations is relevant for a specific item. For us at Amazon, the challenge of tracking inventory at massive scale is not just theoretical, but very real.
Graph databases at Amazon
Like many AWS innovations, the desire to build a solution for a scalable graph database came from Amazon’s retail business. Amazon runs one of the largest fulfillment networks in the world, and we need to optimize our systems to quickly and accurately track the movement of vast amounts of inventory. This requires a database that can quickly traverse the logistics history for a given item or order. Graph databases are ideal for the task, since they make it easy to store and retrieve each item’s logistics history.
Our criteria for choosing the right graph engine were:
- The ability to support a graph containing billions of vertices and edges.
- The ability to scale with the accelerating pace of new items added to the catalog, and new objects and locations in the company’s expanding fulfillment network.
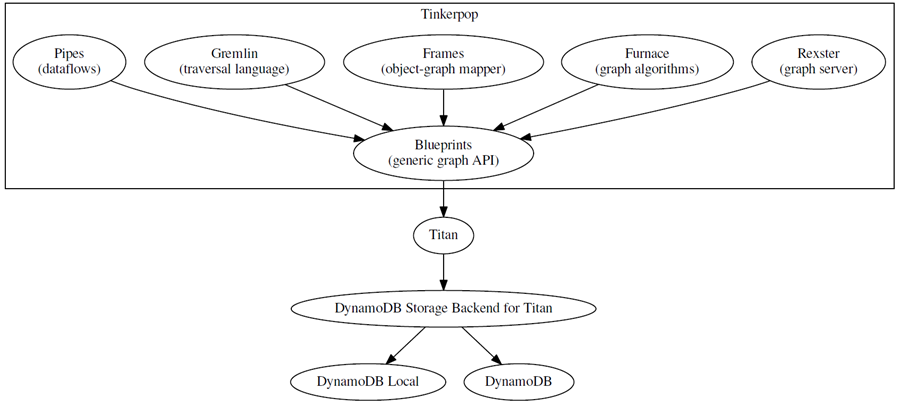
After evaluating different technologies, we decided to use Titan, a distributed graph database engine optimized for creating and querying large graphs. Titan has a pluggable storage architecture, using existing NoSQL databases as underlying storage for the graph data. While the Titan-based solution worked well for our needs, the team quickly found itself having to devote an increasing amount of time to provisioning, managing, and scaling the database cluster behind Titan, instead of focusing on their original task of optimizing the fulfillment inventory tracking.
Thus, the idea was born for a robust, highly available, and scalable backend solution that wouldn’t require the burden of managing a massive storage layer. As I wrote in the past, I believe DynamoDB is a natural choice for such needs, providing developers flexibility and minimal operational overhead without compromising scale, availability, durability, or performance. Making use of Titan’s flexible architecture, we created a plugin that uses DynamoDB as the storage backend for Titan. The combination of Titan with DynamoDB is now powering Amazon’s fulfillment network, with a multi-terabyte dataset.
Sharing it with you
Today, we are happy to bring the result of this effort to customers by releasing the DynamoDB Storage Backend for Titan plugin on GitHub. The plugin provides a flexible data model for each Titan backend table, allowing developers to optimize for simplicity (single-item model) or scalability (multi-item model).
The single-item model uses a single DynamoDB item to store edges and properties of a vertex. In DynamoDB, the vertex ID is stored as the hash key of an item, vertex property and edge identifiers are attribute names, and the vertex property values and edge property values are stored in the respective attribute values. While the single-item data model is simpler, due to DynamoDB’s 400 KB item size limit, you should only use it for graphs with fairly low vertex degree and small number properties per vertex.
For graphs with higher vertex degrees, the multi-item model uses multiple DynamoDB items to store properties and edges of a single vertex. In the multiple-item data model, the vertex ID remains the DynamoDB hash key, but unlike the single-item model, each column becomes the range key in its own item. Each column value is stored in its own attribute. While requiring more writes to initially load the graph, the multiple-item model allows you to store large graphs without limiting vertex degree.
Amazon’s need for a hassle-free, scalable Titan solution is not unique. Many of our customers told us they have used Titan as a scalable graph solution, but setting up and managing the underlying storage are time-consuming chores. Several of them participated in a preview program for the plugin and are excited to offload their graph storage management to AWS. Brian Sweatt, Technical Advisor at AdAgility, explained:
“At AdAgility, we store data pertaining to advertisers and publishers, as well as transactional data about customers who view and interact with our offers. The relationships between these stakeholders lend themselves naturally to a graph database, and we plan to leverage our experience with Titan and Groovy for our next-generation ad targeting platform. Amazon's integration between Titan and DynamoDB will allow us to do that without spending time on setting up and managing the storage cluster, a no brainer for an agile, fast-growing startup.”
Another customer says that AWS makes it easier to analyze large graphs of data and relationships within the data. According to Tom Soderstrom, Chief Technology Officer at NASA’s Jet Propulsion Laboratory:
“We have begun to leverage graph databases extensively at JPL and running deep machine learning on these. The open sourced plugin for Titan over DynamoDB will help us expand our use cases to larger data sets, while enjoying the power of cloud computing in a fully managed NoSQL database. It is exciting to see AWS integrate DynamoDB with open sourced projects like Elasticsearch and Titan, while open sourcing the integrations.”
Bringing it all together
When building applications that are centered on relationships (such as social networks or master data management) or auxiliary relationship-focused use cases for existing applications (such as a recommendation engine for matching players in a game or fraud detection for a payment system), a graph database is an intuitive and effective way to achieve fast performance at scale, and should be on your database options shortlist. With this launch of the DynamoDB storage backend for Titan, you no longer need to worry about managing the storage layer for your Titan graphs, making it easy to manage even very large graphs like the ones we have here at Amazon. I am excited to hear how you are leveraging graph databases for your applications. Please share your thoughts in the comment section below.
For more information about the DynamoDB storage backend plug-in for Titan, see Jeff Barr’s blog and the Amazon DynamoDB Storage Backend for Titan topic in the Amazon DynamoDB Developer Guide








 The
The