Wednesday, November 30, 2016
A Premium Alexa Speaker with 7-inch Touchscreen?
According to a Press Release made by Amazon on Businesswire, millions of Alexa devices were purchased during the Thanksgiving weekend (Black Friday to Cyber Monday). The Echo, Dot, Fire TV Stick with Alexa Remote and Fire tablet weren't only the best-selling Amazon devices, but the best-selling products from any manufacturer in ANY category … Continue reading A Premium Alexa Speaker with 7-inch Touchscreen? 
Bringing the Magic of Amazon AI and Alexa to Apps on AWS.

From the early days of Amazon, Machine learning (ML) has played a critical role in the value we bring to our customers. Around 20 years ago, we used machine learning in our recommendation engine to generate personalized recommendations for our customers. Today, there are thousands of machine learning scientists and developers applying machine learning in various places, from recommendations to fraud detection, from inventory levels to book classification to abusive review detection. There are many more application areas where we use ML extensively: search, autonomous drones, robotics in fulfillment centers, text processing and speech recognition (such as in Alexa) etc.
Among machine learning algorithms, a class of algorithms called deep learning has come to represent those algorithms that can absorb huge volumes of data and learn elegant and useful patterns within that data: faces inside photos, the meaning of a text, or the intent of a spoken word.After over 20 years of developing these machine learning and deep learning algorithms and end user services listed above, we understand the needs of both the machine learning scientist community that builds these machine learning algorithms as well as app developers who use them. We also have a great deal of machine learning technology that can benefit machine scientists and developers working outside Amazon. Last week, I wrote a blog about helping the machine learning scientist community select the right deep learning framework from among many we support on AWS such as MxNet, TensorFlow, Caffe, etc.
Today, I want to focus on helping app developers who have chosen to develop their apps on AWS and have in the past developed some of the seminal apps of our times on AWS, such as Netflix, AirBnB, or Pinterest or created internet connected devices powered by AWS such as Alexa and Dropcam. Many app developers have been intrigued by the magic of Alexa and other AI powered products they see being offered or used by Amazon and want our help in developing their own magical apps that can hear, see, speak, and understand the world around them.
For example, they want us to help them develop chatbots that understand natural language, build Alexa-style conversational experiences for mobile apps, dynamically generate speech without using expensive voice actors, and recognize concepts and faces in images without requiring human annotators. However, until now, very few developers have been able to build, deploy, and broadly scale applications with AI capabilities because doing so required specialized expertise (with Ph.D.s in ML and neural networks) and access to vast amounts of data. Effectively applying AI involves extensive manual effort to develop and tune many different types of machine learning and deep learning algorithms (e.g. automatic speech recognition, natural language understanding, image classification), collect and clean the training data, and train and tune the machine learning models. And this process must be repeated for every object, face, voice, and language feature in an application.
Today, I am excited to announce that we are launching three new Amazon AI services that eliminate all of this heavy lifting, making AI broadly accessible to all app developers by offering Amazon's powerful and proven deep learning algorithms and technologies as fully managed services that any developer can access through an API call or a few clicks in the AWS Management Console. These services are Amazon Lex, Amazon Polly, and Amazon Rekognition that will help AWS app developers build these next generation of magical, intelligent apps. Amazon AI services make the full power of Amazon's natural language understanding, speech recognition, text-to-speech, and image analysis technologies available at any scale, for any app, on any device, anywhere.
Amazon Lex
After the launch of the Alexa Skill Kit (ASK), customers loved the ability to build voice bots or skills for Alexa. They also started asking us to give them access to the technology that powers Alexa, so that they can add a conversational interface (using voice or text) to their mobile apps. They also wanted the capability to publish their bots on chat services like Facebook Messenger and Slack.
Amazon Lex is a new service for building conversational interfaces using voice and text. The same conversational engine that powers Alexa is now available to any developer, making it easy to bring sophisticated, natural language 'chatbots' to new and existing applications. The power of Alexa in the hands of every developer, without having to know deep learning technologies like speech recognition, has the potential of sparking innovation in entirely new categories of products and services. Developers can now build powerful conversational interfaces quickly and easily, that operate at any scale, on any device.

The speech recognition and natural language understanding technology behind Amazon Lex and Alexa is powered by deep learning models that have been trained on massive amounts of data. Developers can simply specify a few sample phrases and the information required to complete a user's task, and Lex builds the deep learning based intent model, guides the conversation, and executes the business logic using AWS Lambda. Developers can build, test, and deploy chatbots directly from the AWS Management Console. These chatbots can be accessed anywhere: from web applications, chat and messenger apps such as Facebook Messenger (with support for exporting to Alexa Skills Kit and Slack support coming soon), or connected devices. Developers can also effortlessly include their Amazon Lex bots in their own iOS and Android mobile apps using the new Conversational Bots feature in AWS Mobile Hub.
Recently, a few selected customers participated in a private beta of Amazon Lex. They provided us with valuable feedback as we rounded off Amazon Lex for a preview launch. I am excited to share some of the feedback from our beta customers HubSpot and Capital One.
HubSpot, a marketing and sales software leader, uses a chatbot called GrowthBot to help marketers and sales personnel be more productive by providing access to relevant data and services. Dharmesh Shah, HubSpot CTO and Founder, tells us that Amazon Lex enabled sophisticated natural language processing capabilities on GrowthBot to provide a more intuitive UI for customers. Hubspot could take advantage of advanced AI and ML capabilities provided by Amazon Lex, without having to code the algorithms.
Capital One offers a broad spectrum of financial products and services to consumers, small businesses, and commercial clients through a variety of channels. Firoze Lafeer, CTO Capital One Labs, tells us that Amazon Lex enables customers to query for information through voice or text in natural language and derive key insights into their accounts. Because Amazon Lex is powered by Alexa's technology, it provides Capital One with a high level of confidence that customer interactions are accurate, allowing easy deployment and scaling of bots.
Amazon Polly
The concept of a computer being able to speak with a human-like voice goes back almost as long as ENIAC (the first electronic programmable computer). The concept has been explored by many popular science fiction movies and TV shows, such as "2001: A Space Odyssey" with HAL-9000 or the Star Trek computer and Commander Data, which defined the perception of computer-generated speech.
Text-to-speech (TTS) systems have been largely adopted in a variety of real-life scenarios such as telephony systems with automated speech responses or help for visually or speech-impaired people. Prof. Stephen Hawking's voice is probably the most famous example of synthetic speech used to help the disabled.
TTS systems have continuously evolved through the last few decades and are nowadays capable of delivering a fairly natural-sounding speech. Today, TTS is used in a large variety of use cases and is turning into a ubiquitous element of user interfaces. Alexa and its TTS voice is yet another step towards building an intuitive and natural language interface that follows the pattern of human communication.
With Amazon Polly, we are making the same TTS technology used to build Alexa's voice to AWS customers. It is now available to any developer aiming to power their apps with high-quality spoken output.
In order to mimic human speech, we needed to address a variety of challenges. We needed to learn how to interpret various text structures such as acronyms, abbreviations, numbers, or homographs (words spelled the same but pronounced differently and having different meanings). For example:
I heard that Outlander is a good read, though I haven't read it yet, or
or
St. Mary's Church is at 226 St. Mary's St.
Last but not least, as the quality of TTS gets better and better, we expect a natural intonation matching the semantics of synthesized texts. Traditional rule-based models and ML techniques, such as classification and regression trees (CART) and hidden Markov models (HMM) present limitations to model the complexity of this process. Deep learning has shown its capacity in representing complex and nonlinear relationships at different levels of speech synthesis process. The TTS technology behind Amazon Polly takes advantage of bidirectional long short-term memory (LSTM) networks using a massive amount of data to train models that convert letters to sounds and predict the intonation contour. This technology enables high naturalness, consistent intonation, and accurate processing of texts.
Amazon Polly customers have confirmed the high quality of generated speech for their use cases. Duolingo uses Amazon Polly voices for language learning applications, where quality is critical. Severin Hacker, the CTO of Duolingo, acknowledged that Amazon Polly voices are not just high in quality, but are as good as natural human speech for teaching a language.
The Royal National Institute of Blind People uses the Amazon TTS technology to support the visually impaired through their largest library of books in the UK. John Worsfold, Solutions Implementation Manager at RNIB, confirmed that Amazon Polly's incredibly lifelike voices captivate and engage RNIB readers.
Amazon Rekognition
We live in a world that is undergoing digital transformation at a rapid rate. One key outcome of this is the explosive growth of images generated and consumed by applications and services across different segments and industries. Whether it is a consumer app for photo sharing or printing, or the organization of images in the archives of media and news organizations, or filtering images for public safety and security, the need to derive insight from the visual content of the images continues to grow rapidly.
There is an inherent gap between the number of images created and stored, and the ability to capture the insight that can be derived from these images. Put simply, most image stores are not searchable, organized, or actionable. While a few solutions exist, customers have told us that they don't scale well, are not reliable, are too expensive, rely on complex pipelines to annotate, verify, and process massive amount of data for training and testing algorithms, need a team of highly specialized and skilled data scientists, and require costly and highly specialized hardware. For companies that have successfully built a pipeline for image analysis, the processes of maintaining, improving, and keeping up with the research in this space proves to be high friction. Amazon Rekognition solves these problems.
Amazon Rekognition is a fully managed, deep-learning–based image analysis service, built by our computer vision scientists with the same proven technology that has already analyzed billions of images daily on Amazon Prime Photos. Amazon Rekognition democratizes the application of deep learning technique for detecting objects, scenes, concepts, and faces in your images, comparing faces between two images, and performing search functionality across millions of facial feature vectors that your business can store with Amazon Rekognition. Amazon Rekognition's easy-to-use API, which is integrated with Amazon S3 and AWS Lambda, brings deep learning to your object store.
Getting started with Rekognition is simple. Let's walk through some of the core features of Rekognition that help you build powerful search, filter, organization, and verification applications for images.
Object and scene detection
Given an image, Amazon Rekognition detects objects, scenes, and concepts and then generates labels, each with a confidence score. Businesses can use this metadata to create searchable indexes for social sharing and printing apps, categorization for news and media image archives, or filters for targeted advertisement. If you are uploading your images to Amazon S3, it is easy to invoke an AWS Lambda function that passes the image to Amazon Rekognition and persist the labels with confidence scores into an Elasticsearch index.

Facial Analysis
With any given image, you can now detect faces present, and derive face attributes like demographic information, sentiment, and key landmarks from the face. With this fast and accurate API, retail businesses can respond to their customers online or in store immediately by delivering targeted ads. Also, these attributes can be stored in Amazon Redshift to generate deeper insights of their customers.

Face recognition
Amazon Rekognition's face comparison and face search features can provide businesses with face-based authentication, verification of identity, and the ability to detect the presence of a specific person in a collection of images. Whether simply comparing faces present in two images using CompareFaces API, or creating a collection of faces by invoking Amazon Rekognition's IndexFace API, businesses can rely on our focus on security and privacy, as no images are stored by Rekognition. Each detected face is transformed into an irreversible vector representation, and this feature vector (and not the underlying image itself) is used for comparison and search.

I am pleased to share some of the positive feedbacks from our beta customers.
Redfin is a full-service brokerage that uses modern technology to help people buy and sell houses. Yong Huang, Director of Big Data & Analytics, Redfin, tell us that Redfin users love to browse images of properties on their site and mobile apps and they want to make it easier for their users to sift through hundreds of millions of listing and images. He also added that Amazon Rekognition generates a rich set of tags directly from images of properties. This makes it relatively simple for them to build a smart search feature that helps customers discover houses based on their specific needs. And, because Amazon Rekognition accepts Amazon S3 URLs, it is a huge time-saver for them to detect objects, scenes, and faces without having to move images around.
Summing it all up
We are in the early days of machine learning and artificial intelligence. As we say in Amazon, we are still in Day 1. Yet, we are already seeing the tremendous value and magical experience Amazon AI can bring to everyday apps. We want to enable all types of developers to build intelligence in to their applications. For data scientists, they can use our P2 instances, Amazon EMR Spark MLLib, deep learning AMIs, MxNet and Amazon ML to build their own ML models. For app developers, we believe that these three Amazon AI services enable them to build next-generation apps to hear, see, and speak with humans and the world around us.
We'll also be hosting a Machine Learning " State of the Union" that covers all the three new AmazonAI services announced today along with demos from Motorola Solutions and Ohio Health – head over to Mirage (as we added more seating!). Also, we have a series of breakout sessions on using MXNet at AWS re:Invent on November 30th at the Mirage Hotel in Las Vegas.
AWS Snowmobile – Move Exabytes of Data to the Cloud in Weeks
Moving large amounts of on-premises data to the cloud as part of a migration effort is still more challenging than it should be! Even with high-end connections, moving petabytes or exabytes of film vaults, financial records, satellite imagery, or scientific data across the Internet can take years or decades. On the business side, adding new networking or better connectivity to data centers that are scheduled to be decommissioned after a migration is expensive and hard to justify.
Last year we announced the AWS Snowball (see AWS Snowball – Transfer 1 Petabyte Per Week Using Amazon-Owned Storage Appliances for more information) as a step toward addressing large-scale data migrations. With 80 TB of storage, these appliances address the needs of many of our customers, and are in widespread use today.
However, customers with exabyte-scale on-premises storage look at the 80 TB, do the math, and realize that an all-out data migration would still require lots of devices and some headache-inducing logistics.
Introducing AWS Snowmobile
In order to meet the needs of these customers, we are launching Snowmobile today. This secure data truck stores up to 100 PB of data and can help you to move exabytes to AWS in a matter of weeks (you can get more than one if necessary). Designed to meet the needs of our customers in the financial services, media & entertainment, scientific, and other industries, Snowmobile attaches to your network and appears as a local, NFS-mounted volume. You can use your existing backup and archiving tools to fill it up with data destined for Amazon Simple Storage Service (S3) or Amazon Glacier.
Physically, Snowmobile is a ruggedized, tamper-resistant shipping container 45 feet long, 9.6 feet high, and 8 feet wide. It is water-proof, climate-controlled, and can be parked in a covered or uncovered area adjacent to your existing data center. Each Snowmobile consumes about 350 kW of AC power; if you don't have sufficient capacity on site we can arrange for a generator.
On the security side, Snowmobile incorporates multiple layers of logical and physical protection including chain-of-custody tracking and video surveillance. Your data is encrypted with your AWS Key Management Service (KMS) keys before it is written. Each container includes GPS tracking, with cellular or satellite connectivity back to AWS. We will arrange for a security vehicle escort when the Snowmobile is in transit; we can also arrange for dedicated security guards while your Snowmobile is on-premises.
Each Snowmobile includes a network cable connected to a high-speed switch capable of supporting 1 Tb/second of data transfer spread across multiple 40 Gb/second connections. Assuming that your existing network can transfer data at that rate, you can fill a Snowmobile in about 10 days.
Snowmobile in Action
I don't happen to have an exabyte-scale data center and I certainly don't have room next to my house for a 45 foot long container. In order to illustrate the process of arranging for and using a Snowmobile, I sat down at my LEGO table and (in the finest Doc Brown tradition) built a scale model. I hope that you enjoy this brick-based story telling!
Let's start in your data center. It was built a while ago and is definitely showing its age. The racks are full of disk and tape drives of multiple vintages, each storing precious, mission-critical data. You and your colleagues spend too much time inside of the raised floor, tracking cables and trying to squeeze out just a bit more performance:

Your manager is getting frustrated and does not know what to do next:

Fortunately, one of your colleagues reads this blog every day and she knows just what to do:

A quick phone call to AWS and a meeting is set up:

Everyone gets together at a convenient AWS office to learn more about Snowmobile and to plan the migration:

Everyone gathers around to look at the scale model of the Snowmobile. Even the dog is intrigued, and your manager takes a picture:

A Snowmobile shows up at your data center:

AWS Professional Services helps you to get it connected and you initiate the data transfer:

The Snowmobile heads back to AWS and your data is imported as you specified!
Snowmobile at DigitalGlobe
Our friends at DigitalGlobe are using a Snowmobile to move 100 PB of satellite imagery to AWS. Here's what Jay Littlepage (former Amazonian and now VP of Infrastructure & Operations at DigitalGlobe) has to say about this effort:
 Like many large enterprises, we are in the process of migrating IT operations from our data centers to AWS. Our geospatial big data platform, GBDX, has been based in AWS since inception. But our unmatchable 16-year archive of high-resolution satellite imagery, visualizing 6 billion square kilometers of the Earth's surface, has been stored within our facilities. We have slowly been migrating our archive to AWS but that process has been slow and inefficient. Our constellation of satellites generate more earth imagery each year (10 PB) than we have been able to migrate by these methods.
Like many large enterprises, we are in the process of migrating IT operations from our data centers to AWS. Our geospatial big data platform, GBDX, has been based in AWS since inception. But our unmatchable 16-year archive of high-resolution satellite imagery, visualizing 6 billion square kilometers of the Earth's surface, has been stored within our facilities. We have slowly been migrating our archive to AWS but that process has been slow and inefficient. Our constellation of satellites generate more earth imagery each year (10 PB) than we have been able to migrate by these methods.
We needed a solution that could move our 100 PB archive but could not find one until now with AWS Snowmobile. DigitalGlobe is currently migrating our entire raw imagery archive with one Snowmobile transfer directly into an Amazon Glacier Vault. AWS Snowmobile operators are providing an amazing customized service where they manage the configuration, monitoring, and logistics. Using Snowmobile's data transfer abilities will get our time-lapse imagery archive to the cloud more quickly, allowing our customers and partners to have access to uniquely massive data sets. By using AWS' elastic computing platform within GBDX, we will run distributed image analysis, revealing the pace and pattern of world-wide change on an extraordinary scale, with unprecedented speed, in a more cost-effective manner – prioritizing insights over infrastructure. Without Snowmobile, we would not have been able to transfer our extremely large volume of data in such a short time or create new business opportunities for our customers. Snowmobile is truly a game changer!
Things to Know
Here are a couple of final things you should know about Snowmobile:
Data Export – The initial launch is aimed at data import (on-premises to AWS). We do know that some of our customers are interested in data export, with a particular focus on disaster recovery (DR) use cases.
Availability – Snowmobile is available in all AWS Regions. As you can see from reading the previous section, this is not a self-serve product. My AWS Sales colleagues are ready to discuss your data import needs with you.
Pricing – I don't have pricing info to share. However, we intend to make sure that Snowmobile is both faster and less expensive than using a network-based data transfer model.
- Jeff;
PS – Check out my Snowmobile Photo Album for some high-res pictures of my creation. Special thanks to Matt Gutierrez (Symbionix) for the final staging and the photo shoot.
PPS – I will build and personally deliver (in exchange for a photo op and a bloggable story) Snowmobile models to the first 5 customers.



Tuesday, November 29, 2016
AWS Global Partner Summit – Report from re:Invent 2016
My colleague Dorothy Copeland is the General Manager for the AWS Global Partner Program. She attended the AWS Global Partner Summit here at AWS re:Invent today and sent a full report, published here as a guest post.
- Jeff;
 We just wrapped an eventful AWS Global Partner Summit at re:Invent. This full-day event is exclusive to AWS Partner Network (APN) Partners. This year, the event featured a keynote with senior AWS leaders, who discussed a number of APN launches, key trends in the market, and stories of APN Partners driving customer success on AWS. The APN team then hosted a number of business and technical sessions focused on topics intended to help APN Partners build a successful AWS-based business.
We just wrapped an eventful AWS Global Partner Summit at re:Invent. This full-day event is exclusive to AWS Partner Network (APN) Partners. This year, the event featured a keynote with senior AWS leaders, who discussed a number of APN launches, key trends in the market, and stories of APN Partners driving customer success on AWS. The APN team then hosted a number of business and technical sessions focused on topics intended to help APN Partners build a successful AWS-based business.
During the Summit, AWS announced that more than 10,000 new Partners have joined the APN in the past 12 months. For customers, this growth provides an expanded selection of software integrated with AWS from thousands of new APN Technology Partners, as well as thousands of new APN Consulting Partners that can help design, architect, build, migrate, and manage their workloads and applications on AWS. Let's take a look at some of the other announcements the APN team made during the Global Partner Summit this year.
During the Global Partner Summit keynote, attendees heard from a number of AWS executives, including:
- Terry Wise
- James Hamilton
- Dave McCann
- Mike Clayville
- Andy Jassy
The keynote also featured the following customer speakers:
- Dan Zelem, CTO, Johnson & Johnson
- Adam Japhet, Head of Technology Services Architecture & Design, Scholastic
Keynote Theme – Driving Customer Success & Innovation on AWS
The world's leading enterprises trust APN Partners to help them achieve the agility benefits of the AWS Cloud. The majority of the Fortune 500 and over 90 percent of Fortune 100 companies utilize APN Partner solutions and services. APN Partners have a unique opportunity to drive customer success on AWS by developing deep skills and specializations on AWS. And throughout the keynote, speakers discussed how APN Partners are successfully helping Enterprise customers drive digital transformation and innovation on AWS, along with key areas of opportunity for APN Partners moving forward. Of particular focus were opportunities APN Partners have to help customers migrate to AWS and maximize the benefits of AWS. Terry Wise discussed how AWS approaches Enterprise migrations, the value of next-generation cloud managed services for customers, and how APN Partners can deliver immense value to customers through automation and full lifecycle customer engagement. Terry also discussed the newly announced alliance with VMWare and VMWare Cloud on AWS. Speaking to innovation, Terry discussed the interesting ways that APN Partners are innovating with Amazon Alexa, and how the APN and Alexa teams work together to help APN Partners develop key Alexa skills.
APN Program Launches
The APN team announced a number of exciting launches during the keynote. Here's a summary, along with links to more information on the AWS Partner Network Blog:
- The AWS IoT Competency: Showcases industry-leading APN Consulting and Technology Partners that provide proven technology and/or implementation capabilities for a variety of IoT use cases including (though not limited to) intelligent factories, smart cities, energy, automotive, transportation, and healthcare.
- The AWS Financial Services Competency: Recognizes APN Consulting and Technology Partners offering services and solutions for customers in banking and payments, capital markets, and insurance.
- The AWS Service Delivery Program: Helps AWS customers find APN Partners with validated experience in specific AWS services and skills such as Amazon Aurora or delivering AWS GovCloud (US) Workloads.
- The AWS Public Sector Program: Helps qualified APN Partners build and accelerate their AWS Public Sector business.
- The AWS Partner Solutions Finder: Enables AWS customers to easily search, discover, and connect with APN Partners, based on their business needs.
Meet Our New AWS Premier Consulting Partners!
We set an extremely high bar for a Consulting Partner to make the Premier tier in the APN (learn more here). We currently have 55 Premier Partners.
Congratulations to the following companies who we announced today have become AWS Premier Consulting Partners:
- Beeva
- Cascadeo
- Claranet Groupe
- InfoReliance
- NEC
- NTT DATA CORPORATION
- Rackspace
- Tata Consultancy Services (TCS)
Join the APN Team at re:Invent
Do you want to learn more about the APN? Visit the APN team at the main AWS booth throughout the week!
Amazon is Now Reselling Frontier Internet Service
Earlier this year, Amazon launched a section on their site called the “Amazon Cable Store” that resells Comcast's internet and television services. At that time, it was the only company featured on the retailer site. Today, Amazon added Frontier which provides high-speed Internet, video, TV and phone services and changed the name into … Continue reading Amazon is Now Reselling Frontier Internet Service 
Monday, November 28, 2016
Toys to Avoid Buying this Holiday Season (10 Worst Toys of 2016)
As we continue with the Dangerous Toys series, let's take a look at the toys marketed to older age groups. Just because your children aren't toddlers or babies anymore, doesn't mean that they are not at risk for toy-related injuries. FYI, in 2014, 183, 000 toy-related injuries were sustained by children younger than … Continue reading Toys to Avoid Buying this Holiday Season (10 Worst Toys of 2016) 
Don't Buy These Toys for your Kids (10 Worst Toys of 2016)
And just like that, Black Friday is over. But that doesn't signal an end to the shopping frenzy. We still have Cyber Monday and a bunch of holiday deals to look forward to. If you haven't bought gifts for the little ones in your life yet, then read this article first before buying … Continue reading Don't Buy These Toys for your Kids (10 Worst Toys of 2016) 
Sunday, November 27, 2016
You Should Not Buy These Toys for your Kids (10 Worst Toys of 2016)
And just like that, Black Friday is over. But that doesn't signal an end to the shopping frenzy. We still have Cyber Monday and a bunch of holiday deals to look forward to. If you haven't bought gifts for the little ones in your life yet, then read this article first before buying … Continue reading You Should Not Buy These Toys for your Kids (10 Worst Toys of 2016)
Friday, November 25, 2016
Had Enough “Black Friday” Yet?
Every year, it seems that “Black Friday” gets even more over-the-top. I have written posts on this topic before. I thought it was crazy enough back when Mrs. Amazopia and I got up at 3am to go down to a local electronics store to see if we could pick up some bargains, and … Continue reading Had Enough “Black Friday” Yet? 
Thursday, November 24, 2016
Judge Orders Delivery Pilots to End the Strike Just in Time for Black Friday
On Tuesday, 250 pilots employed by ABX Air that carries cargo for Amazon and DHL Worldwide Express, went on a strike to protest against intentional understaffing and stressful working conditions. Imagine the holiday horror for Amazon.com and for consumers as well?? Of course, they really chose the “perfect” time of the year to … Continue reading Judge Orders Delivery Pilots to End the Strike Just in Time for Black Friday 
MXNet - Deep Learning Framework of Choice at AWS

Machine learning is playing an increasingly important role in many areas of our businesses and our lives and is being employed in a range of computing tasks where programming explicit algorithms is infeasible.
At Amazon, machine learning has been key to many of our business processes, from recommendations to fraud detection, from inventory levels to book classification to abusive review detection. And there are many more application areas where we use machine learning extensively: search, autonomous drones, robotics in fulfillment centers, text and speech recognitions, etc.
Among machine learning algorithms, a class of algorithms called deep learning hascome to represent those algorithms that can absorb huge volumes of data and learn elegant and useful patterns within that data: faces inside photos, the meaning of a text, or the intent of a spoken word. A set of programming models has emerged to help developers define and train AI models with deep learning; along with open source frameworks that put deep learning in the hands of mere mortals. Some examples of popular deep learning frameworks that we support on AWS include Caffe, CNTK, MXNet, TensorFlow, Theano, and Torch.
Among all these popular frameworks, we have concluded that MXNet is the most scalable framework. We believe that the AI community would benefit from putting more effort behind MXNet. Today, we are announcing that MXNet will be our deep learning framework of choice. AWS will contribute code and improved documentation as well as invest in the ecosystem around MXNet. We will partner with other organizations to further advance MXNet.
AWS and Support for Deep Learning Frameworks
At AWS, we believe in giving choice to our customers. Our goal is to support our customers with tools, systems, and software of their choice by providing the right set of instances, software (AMIs), and managed services. Just like in Amazon RDS―where we support multiple open source engines like MySQL, PostgreSQL, and MariaDB, in the area of deep learning frameworks, we will support all popular deep learning frameworks by providing the best set of EC2 instances and appropriate software tools for them.
Amazon EC2, with its broad set of instance types and GPUs with large amounts of memory, has become the center of gravity for deep learning training. To that end, we recently made a set of tools available to make it as easy as possible to get started: a Deep Learning AMI, which comes pre-installed with the popular open source deep learning frameworks mentioned earlier; GPU-acceleration through CUDA drivers which are already installed, pre-configured, and ready to rock; and supporting tools such as Anaconda and Jupyter. Developers can also use the distributed Deep Learning CloudFormation template to spin up a scale-out, elastic cluster of P2 instances using this AMI for even larger training runs.
As Amazon and AWS continue to invest in several technologies powered by deep learning, we will continue to improve all of these frameworks in terms of usability, scalability, and features. However, we plan to contribute significantly to one in particular, MXNet.
Choosing a Deep Learning Framework
Developers, data scientists, and researchers consider three major factors when selecting a deep learning framework:
- The ability to scale to multiple GPUs (across multiple hosts) to train larger, more sophisticated models with larger, more sophisticated datasets. Deep learning models can take days or weeks to train, so even modest improvements here make a huge difference in the speed at which new models can be developed and evaluated.
- Development speed and programmability, especially the opportunity to use languages they are already familiar with, so that they can quickly build new models and update existing ones.
- Portability to run on a broad range of devices and platforms, because deep learning models have to run in many, many different places: from laptops and server farms with great networking and tons of computing power to mobiles and connected devices which are often in remote locations, with less reliable networking and considerably less computing power.
The same three things are important to developers at AWS and many of our customers. After a thorough evaluation, we have selected MXNet as our deep learning framework of choice , where we plan to use it broadly in existing and upcoming new services.
As part of that commitment, we will be actively promoting and supporting open source development through code contributions (we've made quite a few already), improving the developer experience and documentation online and on AWS, and investing in supporting tools for visualization, development, and migration from other frameworks.
Background on MXNet
MXNet is a fully featured, flexibly programmable, and ultra-scalable deep learning framework supporting state of the art in deep learning models, including convolutional neural networks (CNNs) and long short-term memory networks (LSTMs). MXNet has its roots in academia and came about through the collaboration and contributions of researchers at several top universities. Founding institutions include the University of Washington and Carnegie Mellon University.
"MXNet, born and bred here at CMU, is the most scalable framework for deep learning I have seen, and is a great example of what makes this area of computer science so beautiful - that you have different disciplines which all work so well together: imaginative linear algebra working in a novel way with massive distributed computation leading to a whole new ball game for deep learning. We're excited about Amazon's investment in MXNet, and can't wait to see MXNet go from strength to strength" Andrew Moore – Dean of Computer Science at Carnegie Mellon University.
Scaling MXNet
The efficiency by which a deep learning framework scales out across multiple cores is one of its defining features. More efficient scaling allows you to significantly increase the rate at which you can train new models, or dramatically increase the sophistication of your model for the same amount of training time.
This is an area where MXNet shines: we trained a popular image analysis algorithm, Inception v3 (implemented in MXNet and running on P2 instances), using an increasing number of GPUs. Not only did MXNet have the fastest throughput of any library we evaluated (as measured by the number of images trained per second), but the throughput rose by almost the same rate as the number of GPUs used for training (with a scaling efficiency of 85%).

Developing With MXNet
In addition to scalability, MXNet offers the ability to both mix programming models (imperative and declarative), and code in a wide number of programming languages, including Python, C++, R, Scala, Julia, Matlab, and JavaScript.
Efficient Models & Portability In MXNet
Computational efficiency is important (and goes hand in hand with scalability) but nearly as important is the memory footprint. MXNet can consume as little as 4 GB of memory when serving deep networks with as many as 1000 layers. It is also portable across platforms, and the core library (with all dependencies) fits into a single C++ source file and can be compiled for both Android and iOS. You can even run it in your browser using the JavaScript extensions!
Learn more about MXNet
We're excited about MXNet. If you would like to learn more, you can check out the MXNet home page, or GitHub repository for more information, and can get started right now, using the Deep Learning AMI, or on your own machine. We'll also be hosting a Machine Learning "State of the Union" and a series of breakout sessions and workshops on using MXNet at AWS re:Invent on November 30th at the Mirage Hotel in Las Vegas.
It's still day one for this new era of machine intelligence; in fact, we probably haven't even woken up and had our first cup of coffee yet. With tools like MXNet (and the other deep learning frameworks), and services such as EC2, it's going to be an exciting time.
Use Amazon Aurora for Dev & Test Workloads with new T2.Medium DB Instance Class
Amazon Aurora already allows you to make your choice of five DB instance classes ranging from the db.r3.large (2 vCPUs and 15 GiB of RAM) up to the db.r3.8xlarge (32 vCPUs and 244 GiB of RAM). These instances support a very wide range of production-scale applications and use cases.
Today we giving you a sixth choice, the new db.t2.medium DB instance class with 2 vCPUs and 4 GiB of RAM. Steady-state, this instance class has access to 40% of the performance of a single core, and can burst to full-core performance when processing CPU-intensive queries and other database tasks. Like the similarly-named EC2 instances, this new instance class starts out with a full allocation of CPU Credits, which are spent when the instance is active and accumulate when it is not (my post, New Low Cost EC2 Instances with Burstable Performance, contains a full explanation).
The db.t2.medium should be a great fit for many of your development and test scenarios, and you should also consider them for some of your less-demanding production workloads. You can monitor the CPUCreditUsage and CPUCreditBalance metrics to track the usage and accumulation of credits over tiem.
Now Available
You can create Amazon Aurora database instances that make use of this new DB instance class today. It is available in all regions where Amazon Aurora is currently available. Prices start at $0.082 per hour.
- Jeff;
Tuesday, November 22, 2016
AWS Storage Update – S3 & Glacier Price Reductions + Additional Retrieval Options for Glacier
Back in 2006, we launched S3 with a revolutionary pay-as-you-go pricing model, with an initial price of 15 cents per GB per month. Over the intervening decade, we reduced the price per GB by 80%, launched S3 in every AWS Region, and enhanced the original one-size-fits-all model with user-driven features such as web site hosting, VPC integration, and IPv6 support, while adding new storage options including S3 Infrequent Access.
Because many AWS customers archive important data for legal, compliance, or other reasons and reference it only infrequently, we launched Glacier in 2012, and then gave you the ability to transition data between S3, S3 Infrequent Access, and Glacier by using lifecycle rules.
Today I have two big pieces of news for you: we are reducing the prices for S3 Standard Storage and for Glacier storage. We are also introducing additional retrieval options for Glacier.
S3 & Glacier Price Reduction
As long-time AWS customers already know, we work relentlessly to reduce our own costs, and to pass the resulting savings along in the form of a steady stream of AWS Price Reductions.
We are reducing the per-GB price for S3 Standard Storage in most AWS regions, effective December 1, 2016. The bill for your December usage will automatically reflect the new, lower prices. Here are the new prices for Standard Storage:
| Regions | 0-50 TB ($ / GB / Month) | 51 – 500 TB ($ / GB / Month) | 500+ TB ($ / GB / Month) |
(Reductions range from 23.33% to 23.64%) | $0.0230 | $0.0220 | $0.0210 |
(Reductions range from 20.53% to 21.21%) | $0.0260 | $0.0250 | $0.0240 |
(Reductions range from 24.24% to 24.38%) | $0.0245 | $0.0235 | $0.0225 |
(Reductions range from 16.36% to 28.13%) | $0.0250 | $0.0240 | $0.0230 |
As you can see from the table above, we are also simplifying the pricing model by consolidating six pricing tiers into three new tiers.
We are also reducing the price of Glacier storage in most AWS Regions. For example, you can now store 1 GB for 1 month in the US East (Northern Virginia), US West (Oregon), or EU (Ireland) Regions for just $0.004 (less than half a cent) per month, a 43% decrease. For reference purposes, this amount of storage cost $0.010 when we launched Glacier in 2012, and $0.007 after our last Glacier price reduction (a 30% decrease).
The lower pricing is a direct result of the scale that comes about when our customers trust us with trillions of objects, but it is just one of the benefits. Based on the feedback that I get when we add new features, the real value of a cloud storage platform is the rapid, steady evolution. Our customers often tell me that they love the fact that we anticipate their needs and respond with new features accordingly.
New Glacier Retrieval Options
Many AWS customers use Amazon Glacier as the archival component of their tiered storage architecture. Glacier allows them to meet compliance requirements (either organizational or regulatory) while allowing them to use any desired amount of cloud-based compute power to process and extract value from the data.
Today we are enhancing Glacier with two new retrieval options for your Glacier data. You can now pay a little bit more to expedite your data retrieval. Alternatively, you can indicate that speed is not of the essence and pay a lower price for retrieval.
We launched Glacier with a pricing model for data retrieval that was based on the amount of data that you had stored in Glacier and the rate at which you retrieved it. While this was an accurate reflection of our own costs to provide the service, it was somewhat difficult to explain. Today we are replacing the rate-based retrieval fees with simpler per-GB pricing.
Our customers in the Media and Entertainment industry archive their TV footage to Glacier. When an emergent situation calls for them to retrieve a specific piece of footage, minutes count and they want fast, cost-effective access to the footage. Healthcare customers are looking for rapid, “while you wait” access to archived medical imagery and genome data; photo archives and companies selling satellite data turn out to have similar requirements. On the other hand, some customers have the ability to plan their retrievals ahead of time, and are perfectly happy to get their data in 5 to 12 hours.
Taking all of this in to account, you can now select one of the following options for retrieving your data from Glacier (The original rate-based retrieval model is no longer applicable):
Standard retrieval is the new name for what Glacier already provides, and is the default for all API-driven retrieval requests. You get your data back in a matter of hours (typically 3 to 5), and pay $0.01 per GB along with $0.05 for every 1,000 requests.
Expedited retrieval addresses the need for “while you wait access.” You can get your data back quickly, with retrieval typically taking 1 to 5 minutes. If you store (or plan to store) more than 100 TB of data in Glacier and need to make infrequent, yet urgent requests for subsets of your data, this is a great model for you (if you have less data, S3's Infrequent Access storage class can be a better value). Retrievals cost $0.03 per GB and $0.01 per request.
Retrieval generally takes between 1 and 5 minutes, depending on overall demand. If you need to get your data back in this time frame even in rare situations where demand is exceptionally high, you can provision retrieval capacity. Once you have done this, all Expedited retrievals will automatically be served via your Provisioned capacity. Each unit of Provisioned capacity costs $100 per month and ensures that you can perform at least 3 Expedited Retrievals every 5 minutes, with up to 150 MB/second of retrieval throughput.
Bulk retrieval is a great fit for planned or non-urgent use cases, with retrieval typically taking 5 to 12 hours at a cost of $0.0025 per GB (75% less than for Standard Retrieval) along with $0.025 for every 1,000 requests. Bulk retrievals are perfect when you need to retrieve large amounts of data within a day, and are willing to wait a few extra hours in exchange for a very significant discount.
If you do not specify a retrieval option when you call InitiateJob to retrieve an archive, a Standard Retrieval will be initiated. Your existing jobs will continue to work as expected, and will be charged at the new rate.
To learn more, read about Data Retrieval in the Glacier FAQ.
As always, I am thrilled to be able to share this news with you, and I hope that you are equally excited!
- Jeff;
Sunday, November 20, 2016
New – Web Access for Amazon WorkSpaces
We launched WorkSpaces in late 2013 (Amazon WorkSpaces – Desktop Computing in the Cloud) and have been adding new features at a rapid clip. Here are some highlights from 2016:
- November 2016 – WorkSpaces adds GPU-Powered Graphics Bundles.
- October 2016 – WorkSpaces becomes available in the EU (Frankfurt) Region.
- August 2016 – WorkSpaces offers hourly pricing for all WorkSpaces bundles & AWS Marketplace for Desktop Apps in the Asia Pacific (Singapore) Region.
- July 2016 – WorkSpaces allows you to bring your own Windows 10 desktop licenses.
- June 2016 – WorkSpaces now come with larger root volumes.
- May 2016 – WorkSpaces support tagging.
- April 2016 – AWS Marketplace for Desktop Apps in the EU (Ireland) Region.
- February 2016 – WorkSpaces Application Manager now available in the Asia Pacific (Sydney) and Asia Pacific (Singapore) Regions.
- January 2016 – Support for audio-in, high-DPI devices, and saved registrations.
Today we are adding to this list with the addition of Amazon WorkSpaces Web Access. You can now access your WorkSpace from recent versions of Chrome or Firefox running on Windows, Mac OS X, or Linux. You can now be productive on heavily restricted networks and in situations where installing a WorkSpaces client is not an option. You don't have to download or install anything, and you can use this from a public computer without leaving any private or cached data behind.
To use Amazon WorkSpaces Web Access, simply visit the registration page using a supported browser and enter the registration code for your WorkSpace:
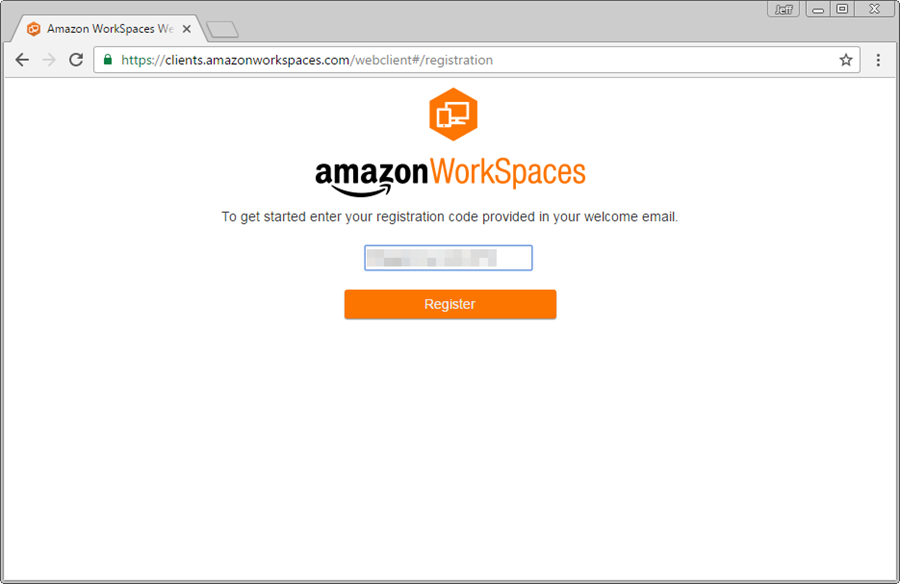
Then log in with your user name and password:
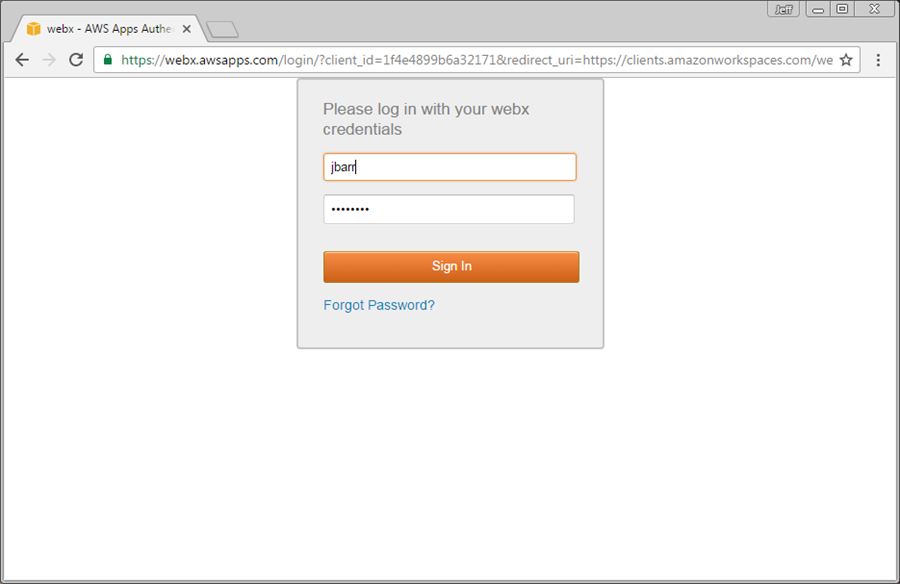
And here you go (yes, this is IE and Firefox running on WorkSpaces, displayed in Chrome):
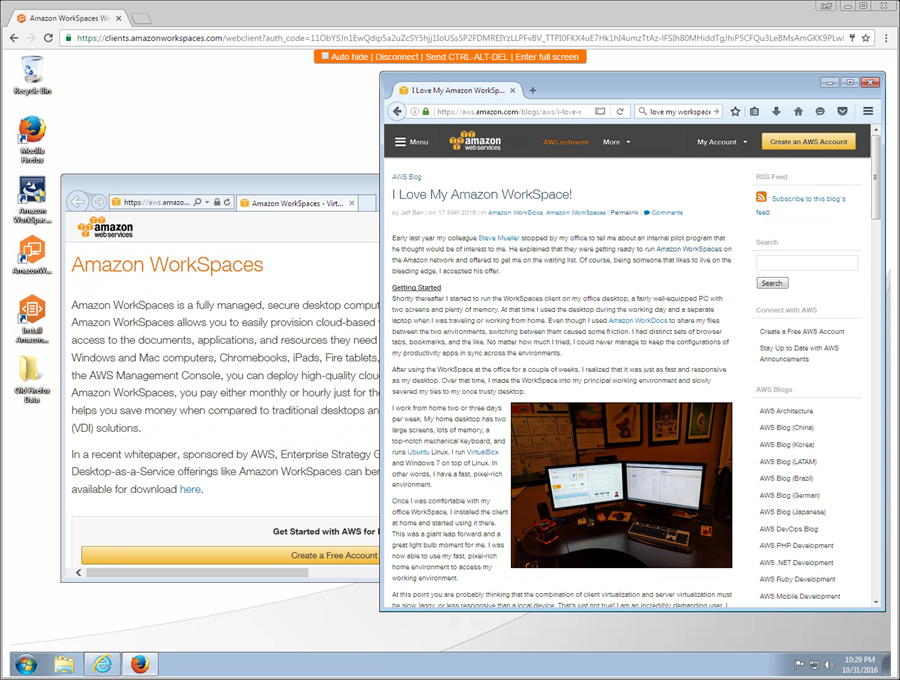
This feature is available for all new WorkSpaces that are running the Value, Standard, or Performance bundles or their Plus counterparts. You can access it at no additional charge after your administrator enables it:
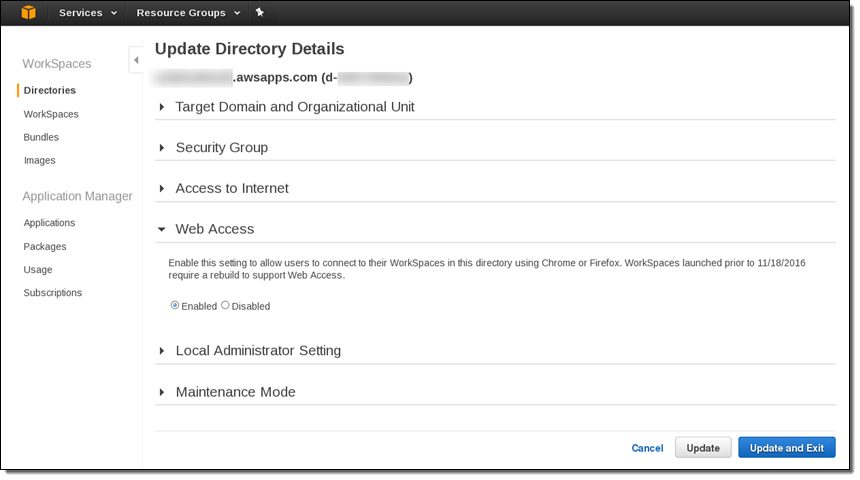
Existing WorkSpaces must be rebuilt and custom images must be refreshed in order to take advantage of Web Access.
- Jeff;
New for AWS Lambda – Environment Variables and Serverless Application Model (SAM)
I am thrilled by all of the excitement that I see around AWS Lambda and serverless application development. I have shared many serverless success stories, tools, and open source projects in the AWS Week in Review over the last year or two.
Today I would like to tell you about two important additions to Lambda: environment variables and the new Serverless Application Model.
Environment Variables
Every developer likes to build code that can be used in more than one environment. In order to do this in a clean and reusable fashion, the code should be able to accept configuration values at run time. The configuration values customize the environment for the code: table names, device names, file paths, and so forth. For example, many projects have distinct configurations for their development, test, and production environments.
You can now supply environment variables to your Lambda functions. This allows you to effect configuration changes without modifying or redeploying your code, and should make your serverless application development even more efficient. Each environment variable is a key/value pair. The keys and the values are encrypted using AWS Key Management Service (KMS) and decrypted on an as-needed basis. There's no per-function limit on the number of environment variables, but the total size can be no more than 4 kb.
When you create a new version of a Lambda function, you also set the environment variables for that version of the function. You can modify the values for the latest version of the function, but not for older versions. Here's how I would create a simple Python function, set some environment variables, and then reference them from my code (note that I had to import the os library):
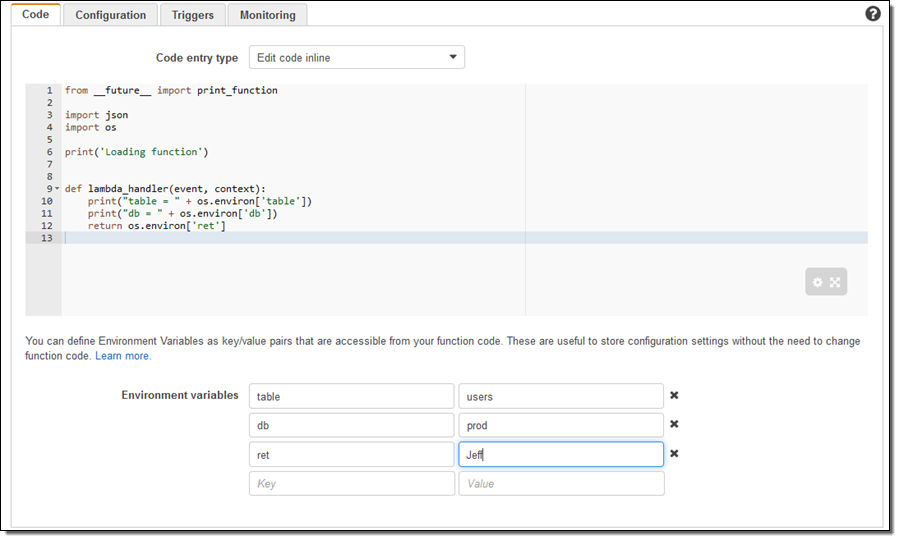
There's no charge for this feature if you use the default service key provided by Lambda (the usual per-request KMS charges apply if you choose to use your own key).
To learn more and to get some ideas for other ways to make use of this new feature, read Simplify Serverless Applications With Lambda Environment Variables on the AWS Compute Blog.
AWS Serverless Application Model
Lambda functions, Amazon API Gateway resources, and Amazon DynamoDB tables are often used together to build serverless applications. The new AWS Serverless Application Model (AWS SAM) allows you describe all of these components using a simplified syntax that is natively supported by AWS CloudFormation. In order to use this syntax, your CloudFormation template must include a Transform section (this is a new aspect of CloudFormation) that looks like this:
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
The remainder of the template is used to specify the Lambda functions, API Gateway endpoints & resources, and DynamoDB tables. Each function declaration specifies a handler, a runtime, and a URI to a ZIP file that contains the code for the function.
APIs can be declared implicitly by defining events, or explicitly, by providing a Swagger file.
DynamoDB tables are declared using a simplified syntax that requires just a table name, a primary key (name and type), and the provisioned throughput. The full range of options is also available for you to use if necessary.
You can now generate AWS SAM files and deployment packages for your Lamba functions using a new Export operation in the Lambda Console. Simply click on the Actions menu and select Export function:
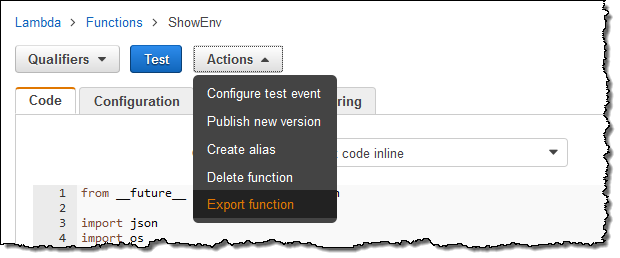
Then click on Download AWS SAM file or Download deployment package:
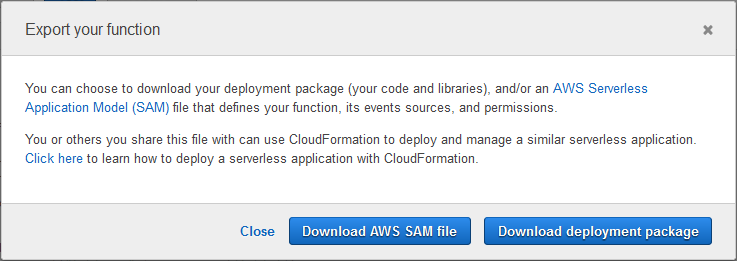
Here is the AWS SAM file for my function:
AWSTemplateFormatVersion: '2010-09-09'
Transform: 'AWS::Serverless-2016-10-31'
Description: A starter AWS Lambda function.
Resources:
ShowEnv:
Type: 'AWS::Serverless::Function'
Properties:
Handler: lambda_function.lambda_handler
Runtime: python2.7
CodeUri: .
Description: A starter AWS Lambda function.
MemorySize: 128
Timeout: 3
Role: 'arn:aws:iam::99999999999:role/LambdaGeneralRole'The deployment package is a ZIP file with the code for my function inside. I would simply upload the file to S3 and update the CodeUri in the SAM file in order to use it as part of my serverless application. You can do this manually or you can use a pair of new CLI commands (aws cloudformation package and aws cloudformation deploy) to automate it. To learn more about this option, read the section on Deploying a Serverless app in the new Introducing Simplified Serverless Application Management and Deployment post.
You can also export Lambda function blueprints. Simply click on the download link in the corner:
And click on Download blueprint:
The ZIP file contains the AWS SAM file and the code:
To learn more and to see this new specification in action, read Introducing Simplified Serverless Application Management and Deployment on the AWS Compute Blog.
- Jeff;
Subscribe to:
Posts (Atom)