My colleague Andrew Thomas wrote the guest post below to introduce you to the new EC2 Container Registry!
— Jeff;
I am happy to announce that Amazon EC2 Container Registry (ECR) is now generally available!
Amazon ECR is a fully-managed Docker container registry that makes it easy for developers to store, manage, and deploy Docker container images. We pre-announced the service at AWS re:Invent and have been receiving a lot of interest and enthusiasm from developers ever since.
We built Amazon ECR because many of you told us that running your own private Docker image registry presented many challenges like managing the infrastructure and handling large scale deployments that involve pulling hundreds of images at once. Self-hosted solutions, you said, are especially hard when deploying container images to clusters that span two or more AWS regions. Additionally, you told us that you needed fine-grained access control to repositories/images without having to manage certificates or credentials.
Amazon ECR was designed to meet all of these needs and more. You do not need to install, operate, or scale your own container registry infrastructure. Amazon ECR hosts your images in a highly available and scalable architecture, allowing you to reliably deploy containers for your applications. Amazon ECR is also highly secure. Your images are transferred to the registry over HTTPS and automatically encrypted at rest in S3. You can configure policies to manage permissions and control access to your images using AWS Identity and Access Management (IAM) users and roles without having to manage credentials directly on your EC2 instances. This enables you to share images with specific users or even AWS accounts.
Amazon EC2 Container Registry also integrates with Amazon ECS and the Docker CLI, allowing you to simplify your development and production workflows. You can easily push your container images to Amazon ECR using the Docker CLI from your development machine, and Amazon ECS can pull them directly for production deployments.
Let’s take a look at how easy it is to store, manage, and deploy Docker containers with Amazon ECR and Amazon ECS.
Amazon ECR Console
The Amazon ECR Console simplifies the process of managing images and setting permissions on repositories. To access the console, simply navigate to the “Repositories” section in the Amazon ECS console. In this example I will push a simple PHP container image to Amazon ECR, configure permissions, and deploy the image to an Amazon ECS cluster.
After navigating to the Amazon ECR Console and selecting “Get Started”, I am presented with a simple wizard to create and configure my repository.
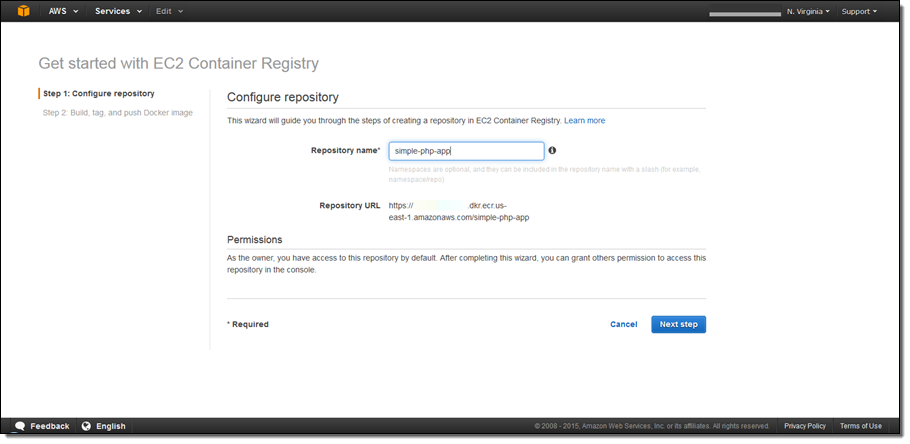
After entering the repository name, I see the repository endpoint URL that I will use to access Amazon ECR. By default I have access to this repository, so I don’t have to worry about permissions now and can set them later in the ECR console.
When I click Next step, I see the commands I need to run in my terminal to build my Docker image and push it to the repository I just created. I am using the Dockerfile from the ECS Docker basics tutorial. The commands that appear in the console require that I have the AWS Command Line Interface (CLI) and Docker CLI installed on my development machine. Next, I copy and run each command to login, tag the image with the ECR URI, and push the image to my repository.
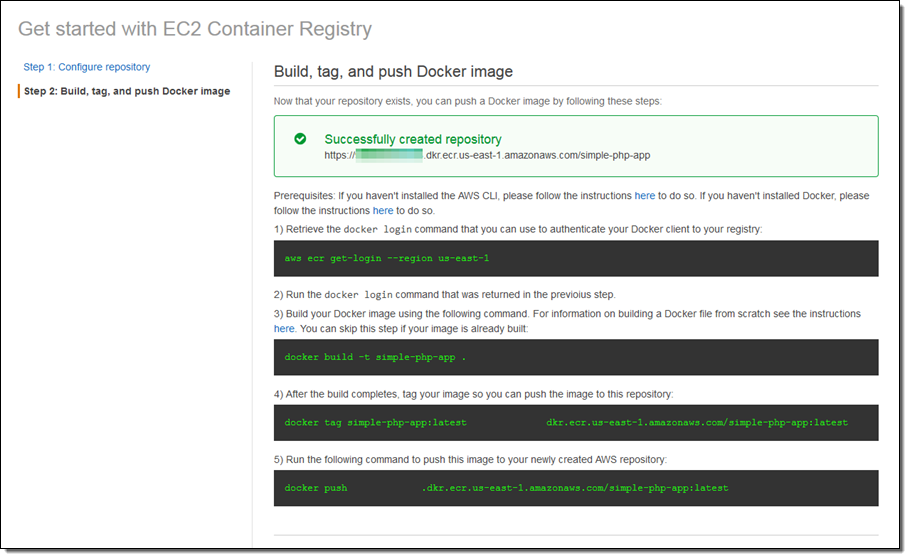
After completing these steps, I click Done to navigate to the repository where I can manage my images.
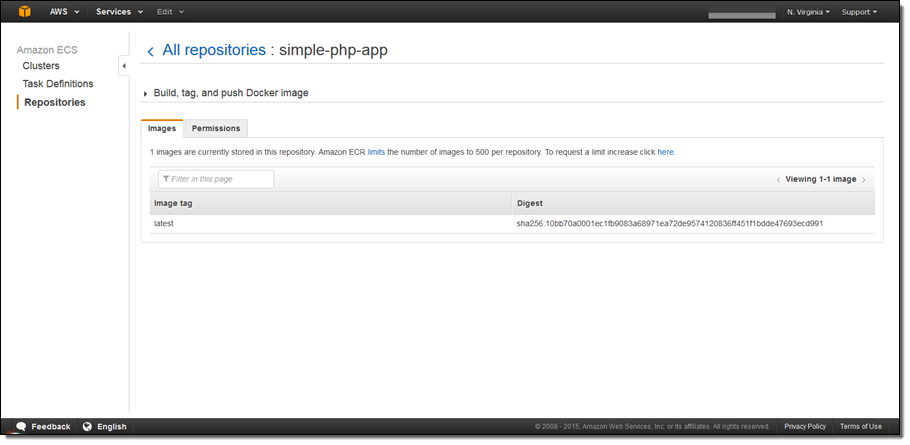
Setting Permissions
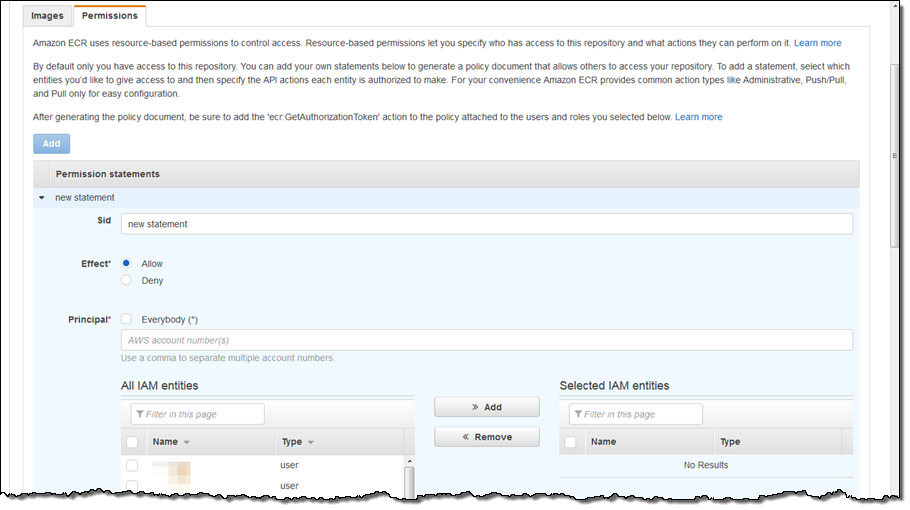
Amazon ECR uses AWS Identity and Access Management to control and monitor who and what (e.g., EC2 instances) can access your container images. We built a permissions tool in the Amazon ECR Console to make it easier to create resource-based policies for your repositories.
To use the tool I click on the Permissions tab in the repository and select Add. I now see that the fields in the form correspond to an IAM statement within a policy document. After adding the statement ID, I select whether this policy should explicitly deny or allow access. Next I can set who this statement should apply to by either entering another AWS account number or selecting users and roles in the entities table.
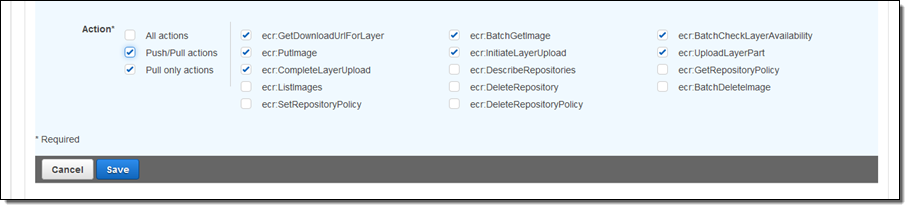
After selecting the desired entities, I can then configure the actions that should apply to the statement. For convenience, I can use the toggles on the left to easily select the actions required for pull, push/pull, and administrative capabilities.
Integration With Amazon ECS
Once I’ve created the repository, pushed the image, and set permissions I am now ready to deploy the image to ECS.
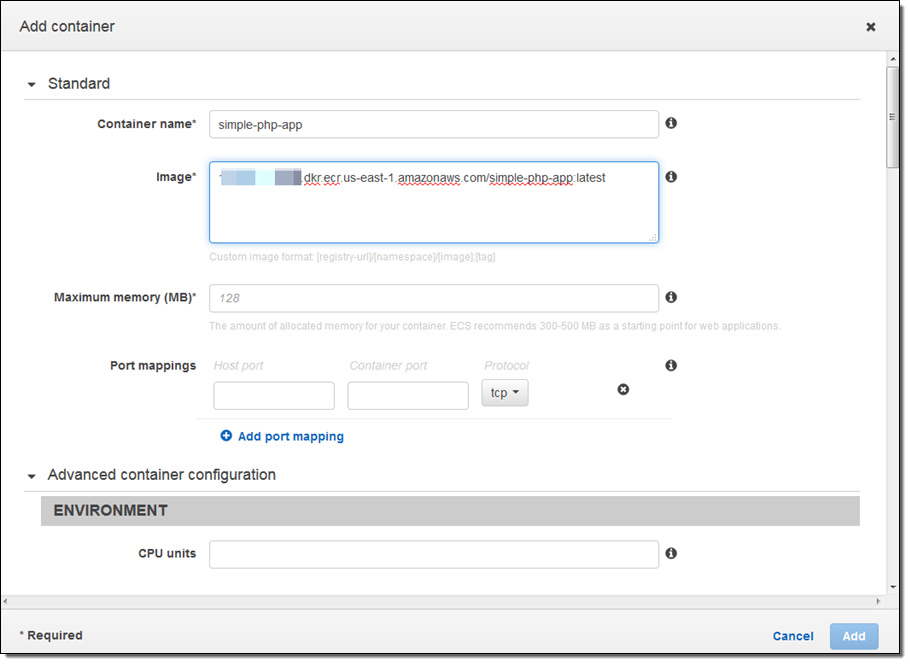
Navigating to the Task Definitions section of the ECS console, I create a new Task Definition and specify the Amazon ECR repository in the Image field. Once I’ve configured the Task Definition, I can go to the Clusters section of the console and create a new service for my Task Definition. After creating the service, the ECS Agent will automatically pull down the image from ECR and start running it on an ECS cluster.
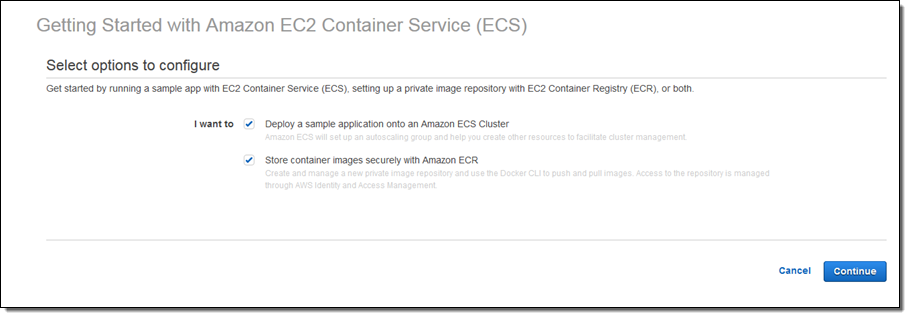
Updated First-Run
We have also updated our Amazon ECS Getting Started Wizard to include the ability to push an image to Amazon ECR and deploy that image to ECS:
Partner Support for ECS
At re:Invent we announced partnerships with a number of CI/CD providers to help automate deploying containers on ECS. We are excited to announce today that our partners have added support for Amazon ECR making it easy for developers to create and orchestrate a full, end-to-end container pipeline to automatically build, store, and deploy images on AWS. To get started check out the solutions from our launch partners who include Shippable, Codeship, Solano Labs, CloudBees, and CircleCI.
We are also excited to announce a partnership with TwistLock to provide vulnerability scanning of images stored within ECR. This makes it even easier for developers to evaluate potential security threats before pushing to Amazon ECR and allows developers to monitor their containers running in production. See the Container Partners Page for more information about our partnerships.
Launch Region
Effective today, Amazon ECR is available in US East (Northern Virginia) with more regions on the way soon!
Pricing
With Amazon ECR you only pay for the storage used by your images and data transfer from Amazon ECR to the internet or other regions. See the ECR Pricing page for more details.
Get Started Today
Check out our Getting Started with EC2 Container Registry page to start using Amazon ECR today!
— Andrew Thomas, Senior Product Manager




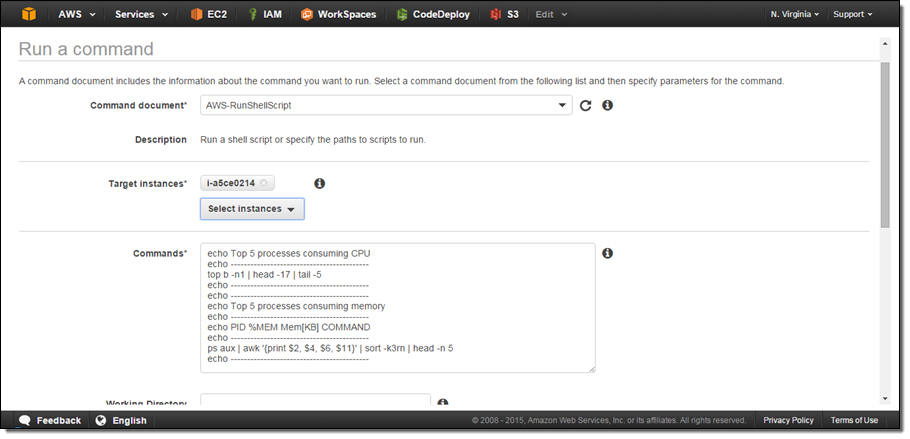
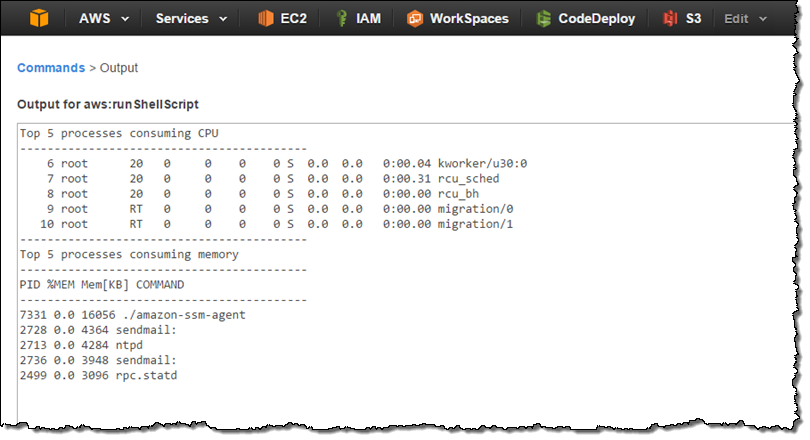
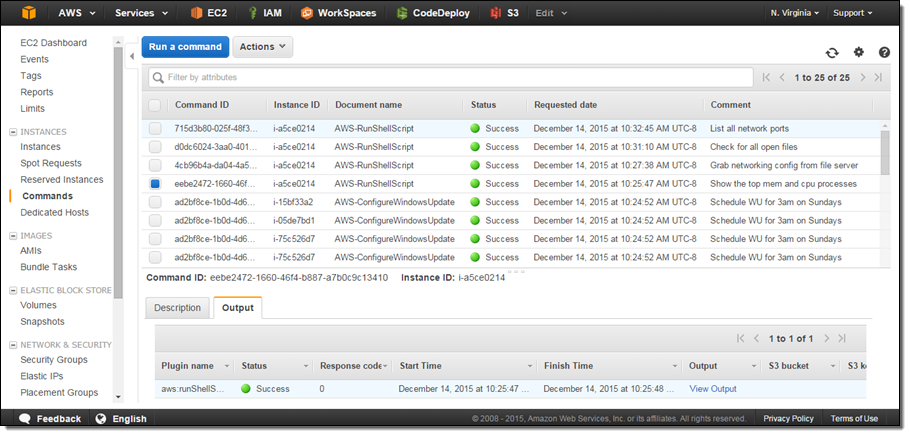
 Then click on Reports in the left navigation:
Then click on Reports in the left navigation: