In today's guest post, Alex Casalboni and Giacomo Marinangeli of Cloud Academy discuss the design and development of their new Inspire system.
-Jeff;
Our Challenge
Mixing technology and content has been our mission at Cloud Academy since the very early days. We are builders and we love technology, but we also know content is king. Serving our members with the best content and creating smart technology to automate it is what kept us up at night for a long time.
Companies are always fighting for people's time and attention and at Cloud Academy, we face those same challenges as well. Our goal is to empower people, help them learn new Cloud skills every month, but we kept asking ourselves: “How much content is enough? How can we understand our customer's goals and help them select the best learning paths?”
With this vision in mind about six months ago we created a project called Inspire which focuses on machine learning, recommendation systems and data analysis. Inspire solves our problem on two fronts. First, we see an incredible opportunity in improving the way we serve our content to our customers. It will allow us to provide better suggestions and create dedicated learning paths based on an individual's skills, objectives and industries. Second, Inspire represented an incredible opportunity to improve our operations. We manage content that requires constant updates across multiple platforms with a continuously growing library of new technologies.
For instance, getting a notification to train on a new EC2 scenario that you're using in your project can really make a difference in the way you learn new skills. By collecting data across our entire product, such as when you watch a video or when you're completing an AWS quiz, we can gather that information to feed Inspire. Day by day, it keeps personalising your experience through different channels inside our product. The end result is a unique learning experience that will follow you throughout your entire journey and enable a customized continuous training approach based on your skills, job and goals.
Inspire: Powered by AWS
Inspire is heavily based on machine learning and AI technologies, enabled by our internal team of data scientists and engineers. Technically, this involves several machine learning models, which are trained on the huge amount of collected data. Once the Inspire models are fully trained, they need to be deployed in order to serve new predictions, at scale.
Here the challenge has been designing, deploying and managing a multi-model architecture, capable of storing our datasets, automatically training, updating and A/B testing our machine learning models, and ultimately offering a user-friendly and uniform interface to our website and mobile apps (available for iPhone and Android).
From the very beginning, we decided to focus high availability and scalability. With this in mind, we designed an (almost) serverless architecture based on AWS Lambda. Every machine learning model we build is trained offline and then deployed as an independent Lambda function.
Given the current maximum execution time of 5 minutes, we still run the training phase on a separate EC2 Spot instance, which reads the dataset from our data warehouse (hosted on Amazon RDS), but we are looking forward to migrating this step to a Lambda function as well.
We are using Amazon API Gateway to manage RESTful resources and API credentials, by mapping each resource to a specific Lambda function.
The overall architecture is logically represented in the diagram below:
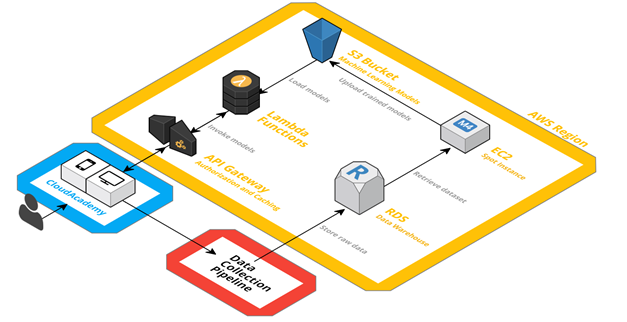
Both our website and mobile app can invoke Inspire with simple HTTPS calls through API Gateway. Each Lambda function logically represents a single model and aims at solving a specific problem. More in detail, each Lambda function loads its configuration by downloading the corresponding machine learning model from Amazon S3 (i.e. a serialized representation of it).
Behind the scenes, and without any impact on scalability or availability, an EC2 instance takes care of periodically updating these S3 objects, as outcome of the offline training phase.
Moreover, we want to A/B test and optimize our machine learning models: this is transparently handled in the Lambda function itself by means of SixPack, an open-source A/B testing framework which uses Redis.
Data Collection Pipeline
As far as data collection is concerned, we use Segment.com as data hub: with a single API call, it allows us to log events into multiple external integrations, such as Google Analytics, Mixpanel, etc. We also developed our own custom integration (via webhook) in order to persistently store the same data in our AWS-powered data warehouse, based on Amazon RDS.
Every event we send to Segment.com is forwarded to a Lambda function – passing through API Gateway – which takes care of storing real-time data into an SQS queue. We use this queue as a temporary buffer in order to avoid scalability and persistency problems, even during downtime or scheduled maintenance. The Lambda function also handles the authenticity of the received data thanks to a signature, uniquely provided by Segment.com.
Once raw data has been written onto the SQS queue, an elastic fleet of EC2 instances reads each individual event – hence removing it from the queue without conflicts – and writes it into our RDS data warehouse, after performing the required data transformations.

The serverless architecture we have chosen drastically reduces the costs and problems of our internal operations, besides providing high availability and scalability by default.
Our Lambda functions have a pretty constant average response time – even during load peaks – and the SQS temporary buffer makes sure we have a fairly unlimited time and storage tolerance before any data gets lost.
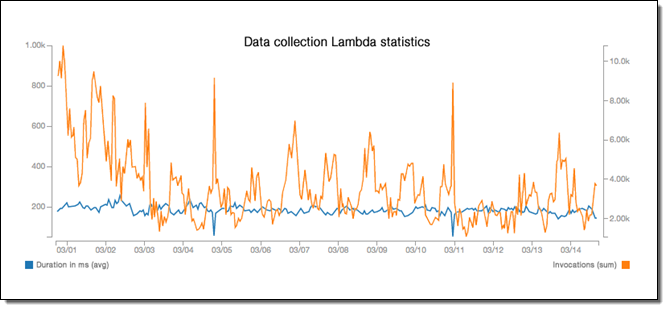
At the same time, our machine learning models won't need to scale up in a vertical or distributed fashion since Lambda takes care of horizontal scaling. Currently, they have an incredibly low average response time of 1ms (or less):
We consider Inspire an enabler for everything we do from a product and content perspective, both for our customers and our operations. We've worked to make this the core of our technology, so that its contributions can quickly be adapted and integrated by everyone internally. In the near future, it will be able to independently make decisions for our content team while focusing on our customers' need. At the end of the day, Inspire really answers our team's doubts on which content we should prioritize, what works better and exactly how much of it we need. Our ultimate goal is to improve our customer's learning experience by making Cloud Academy smarter by building real intelligence.
Join our Webinar
If you would like to learn more about Inspire, please join our April 27th webinar – How we Use AWS for Machine Learning and Data Collection.
- Alex Casalboni, Senior Software Engineer, Cloud Academy
- Giacomo Marinangeli, CTO, Cloud Academy
PS – Cloud Academy is hiring – check out our open positions!



No comments:
Post a Comment