Thursday, April 28, 2016
Discounted Kindle and Fire Tablets for Mother's Day
If you are looking for the perfect Mother's Day gift or in the market for a new tablet, then you're in luck because Amazon is giving big discounts on several Kindle and Fire tablets. Aside from the e-commerce site, Amazon also authorized Best Buy to mark down their prices. On Amazon, you get … Continue reading Discounted Kindle and Fire Tablets for Mother's Day 
They're Here – Longer EBS and Storage Gateway Resource IDs Now Available
Last November I let you know that were were planning to increase the length of the resource IDs for EC2 instances, reservations, EBS volumes, and snapshots in 2016. Early this year I showed you how to opt in to the new format for EC2 instances and EC2 reservations.
Effective today you can now opt in to the new format for volumes and snapshots for EBS and Storage Gateway.
As I said earlier:
If you build libraries, tools, or applications that make direct calls to the AWS API, now is the time to opt in and to start your testing process! If you store the IDs in memory or in a database, take a close look at fixed-length fields, data structures, schema elements, string operations, and regular expressions. Resources that were created before you opt in will retain their existing short identifiers; be sure that your revised code can still handle them!
You can opt in to the new format using the AWS Management Console, the AWS Command Line Interface (CLI), the AWS Tools for Windows PowerShell, or by calling the ModifyIdFormat API function.
Opting In – Console
To opt in via the Console, simply log in, choose EC2, and click on Resource ID length management:
Then click on Use Longer IDs for the desired resource types:
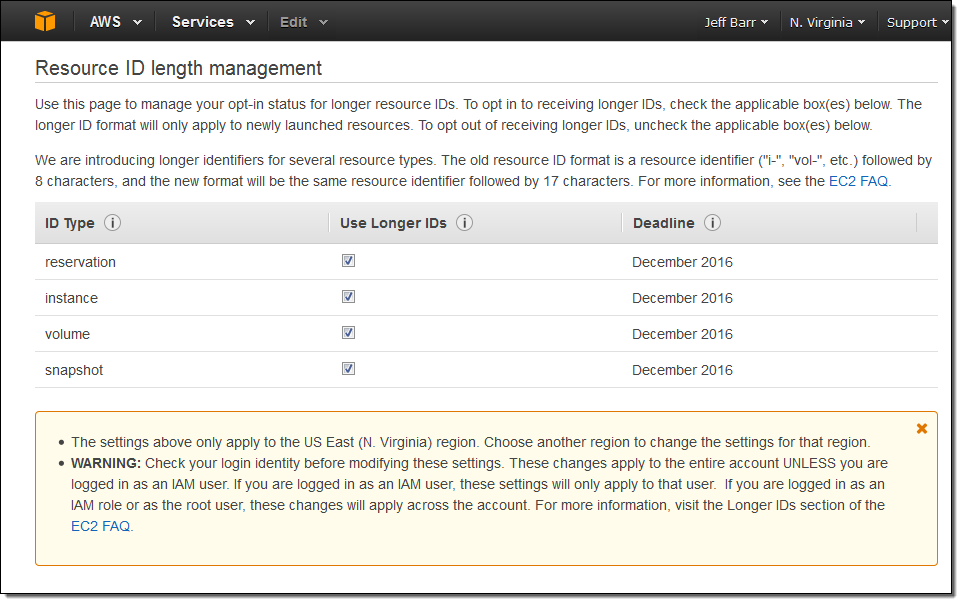
Note that volume applies to EBS volumes and to Storage Gateway volumes and that snapshot applies to EBS snapshots (both direct and through Storage Gateway).
For information on using the AWS Command Line Interface (CLI) or the AWS Tools for Windows PowerShell, take a look at They're Here – Longer EC2 Resource IDs Now Available.
Things to Know
Here are a couple of things to keep in mind as you transition to the new resource IDs:
- Some of the older versions of the AWS SDKs and CLIs are not compatible with the new format. Visit the Longer EC2 and EBS Resource IDs FAQ for more information on compatibility.
- New AWS Regions get longer instance, reservation, volume, and snapshot IDs by default. You can opt out for Regions that launch between now and December 2016.
- Starting on April 28, 2016, new accounts in all commercial regions except Beijing (China) and AWS GovCloud (US) will get longer instance and reservation IDs by default, again with the ability to opt out.
Jeff;



Wednesday, April 27, 2016
Amazon Expands its Free Time Unlimited Subscription
The retail site's all-in-one subscription for kids is now available for tweens ages 9-12. With thousands of age-appropriate vides, apps and books added, your kids will surely enjoy using their Kindle and Fire tablets. “Today, FreeTime Unlimited offers over 13,000 videos, educational apps, games, and books, plus over 40,000 YouTube videos and websites-for kids from … Continue reading Amazon Expands its Free Time Unlimited Subscription 
Tuesday, April 26, 2016
Machine Learning, Recommendation Systems, and Data Analysis at Cloud Academy
In today's guest post, Alex Casalboni and Giacomo Marinangeli of Cloud Academy discuss the design and development of their new Inspire system.
-Jeff;
Our Challenge
Mixing technology and content has been our mission at Cloud Academy since the very early days. We are builders and we love technology, but we also know content is king. Serving our members with the best content and creating smart technology to automate it is what kept us up at night for a long time.
Companies are always fighting for people's time and attention and at Cloud Academy, we face those same challenges as well. Our goal is to empower people, help them learn new Cloud skills every month, but we kept asking ourselves: “How much content is enough? How can we understand our customer's goals and help them select the best learning paths?”
With this vision in mind about six months ago we created a project called Inspire which focuses on machine learning, recommendation systems and data analysis. Inspire solves our problem on two fronts. First, we see an incredible opportunity in improving the way we serve our content to our customers. It will allow us to provide better suggestions and create dedicated learning paths based on an individual's skills, objectives and industries. Second, Inspire represented an incredible opportunity to improve our operations. We manage content that requires constant updates across multiple platforms with a continuously growing library of new technologies.
For instance, getting a notification to train on a new EC2 scenario that you're using in your project can really make a difference in the way you learn new skills. By collecting data across our entire product, such as when you watch a video or when you're completing an AWS quiz, we can gather that information to feed Inspire. Day by day, it keeps personalising your experience through different channels inside our product. The end result is a unique learning experience that will follow you throughout your entire journey and enable a customized continuous training approach based on your skills, job and goals.
Inspire: Powered by AWS
Inspire is heavily based on machine learning and AI technologies, enabled by our internal team of data scientists and engineers. Technically, this involves several machine learning models, which are trained on the huge amount of collected data. Once the Inspire models are fully trained, they need to be deployed in order to serve new predictions, at scale.
Here the challenge has been designing, deploying and managing a multi-model architecture, capable of storing our datasets, automatically training, updating and A/B testing our machine learning models, and ultimately offering a user-friendly and uniform interface to our website and mobile apps (available for iPhone and Android).
From the very beginning, we decided to focus high availability and scalability. With this in mind, we designed an (almost) serverless architecture based on AWS Lambda. Every machine learning model we build is trained offline and then deployed as an independent Lambda function.
Given the current maximum execution time of 5 minutes, we still run the training phase on a separate EC2 Spot instance, which reads the dataset from our data warehouse (hosted on Amazon RDS), but we are looking forward to migrating this step to a Lambda function as well.
We are using Amazon API Gateway to manage RESTful resources and API credentials, by mapping each resource to a specific Lambda function.
The overall architecture is logically represented in the diagram below:
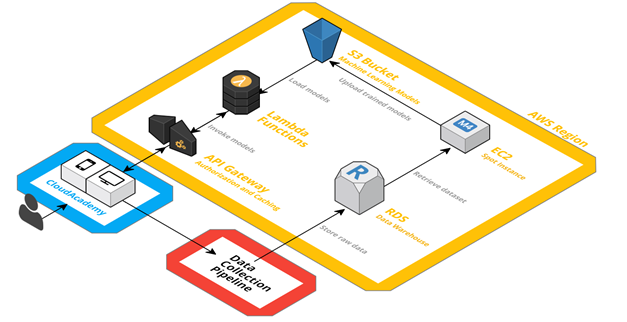
Both our website and mobile app can invoke Inspire with simple HTTPS calls through API Gateway. Each Lambda function logically represents a single model and aims at solving a specific problem. More in detail, each Lambda function loads its configuration by downloading the corresponding machine learning model from Amazon S3 (i.e. a serialized representation of it).
Behind the scenes, and without any impact on scalability or availability, an EC2 instance takes care of periodically updating these S3 objects, as outcome of the offline training phase.
Moreover, we want to A/B test and optimize our machine learning models: this is transparently handled in the Lambda function itself by means of SixPack, an open-source A/B testing framework which uses Redis.
Data Collection Pipeline
As far as data collection is concerned, we use Segment.com as data hub: with a single API call, it allows us to log events into multiple external integrations, such as Google Analytics, Mixpanel, etc. We also developed our own custom integration (via webhook) in order to persistently store the same data in our AWS-powered data warehouse, based on Amazon RDS.
Every event we send to Segment.com is forwarded to a Lambda function – passing through API Gateway – which takes care of storing real-time data into an SQS queue. We use this queue as a temporary buffer in order to avoid scalability and persistency problems, even during downtime or scheduled maintenance. The Lambda function also handles the authenticity of the received data thanks to a signature, uniquely provided by Segment.com.
Once raw data has been written onto the SQS queue, an elastic fleet of EC2 instances reads each individual event – hence removing it from the queue without conflicts – and writes it into our RDS data warehouse, after performing the required data transformations.

The serverless architecture we have chosen drastically reduces the costs and problems of our internal operations, besides providing high availability and scalability by default.
Our Lambda functions have a pretty constant average response time – even during load peaks – and the SQS temporary buffer makes sure we have a fairly unlimited time and storage tolerance before any data gets lost.
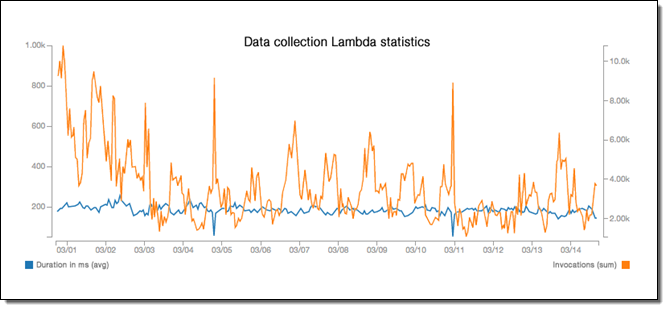
At the same time, our machine learning models won't need to scale up in a vertical or distributed fashion since Lambda takes care of horizontal scaling. Currently, they have an incredibly low average response time of 1ms (or less):
We consider Inspire an enabler for everything we do from a product and content perspective, both for our customers and our operations. We've worked to make this the core of our technology, so that its contributions can quickly be adapted and integrated by everyone internally. In the near future, it will be able to independently make decisions for our content team while focusing on our customers' need. At the end of the day, Inspire really answers our team's doubts on which content we should prioritize, what works better and exactly how much of it we need. Our ultimate goal is to improve our customer's learning experience by making Cloud Academy smarter by building real intelligence.
Join our Webinar
If you would like to learn more about Inspire, please join our April 27th webinar – How we Use AWS for Machine Learning and Data Collection.
- Alex Casalboni, Senior Software Engineer, Cloud Academy
- Giacomo Marinangeli, CTO, Cloud Academy
PS – Cloud Academy is hiring – check out our open positions!
Monday, April 25, 2016
AWS Week in Review – April 18, 2016
Let's take a quick look at what happened in AWS-land last week:
New & Notable Open Source
- amazon-redshift-monitoring uses CloudWatch and Lambda to generate CloudWatch custom alarms.
- amazon-redshift-utils contains utilities, scripts, and views that are useful in a Redshift environment.
- dynamodbtocsv downloads a DynamoDB table and exports the contents in CSV form.
- AndroidPerfTestExample implements automated Android A/B performance testing with AWS Device Farm, New Relic, and TravisCI.
- awsips is a simple Go package which downloads and returns the AWS IP address ranges.
- bootstrap-cfn is an opinionated layer for AWS CloudFormation.
- botoform helps to architect infrastructure on AWS using YAML.
- aws-cloudformation-generator generates a CloudFormation template from a Python object.
- aws-api-gateway-bodyparser parses x-www-form-urlencoded requests into JSON for use with API Gateway.
- chef-provisioning-aws is an AWS driver and a set of resources for Chef that uses the AWS SDK.
New SlideShare Presentations
New Customer Success Stories
New YouTube Videos
- AWS Summit Series 2016 – Chicago:
- Keynote.
- Getting Started with Amazon Redshift.
- Big Data Architectural Patterns and Best Practices on AWS.
- Another Day, Another Billion Packets.
- Getting Started with Amazon DynamoDB.
- Containers and the Evolution of Computing.
- Deep Dive on Amazon DynamoDB.
- Getting Started with Amazon Enterprise Applications.
- Getting Started with Amazon EC2 and Compute Services.
- Deep Dive on Microservices and Amazon ECS.
- Deep Dive on Amazon Aurora.
- Getting Started with AWS IoT.
- AWS Data Transfer Services: Accelerating Large-Scale Data Ingest.
- Cost Optimization at Scale.
- Amazon WorkSpaces and Amazon WorkSpaces Application Manager.
- Getting Started with Amazon Aurora.
Upcoming Events
- AWS Webinars – April 2016.
- AWS Zombie Microservices Roadshow.
- April 27 – Live Event (Rio de Janeiro, Brazil) – AWS Meetup.
- April 27 – Live Event (Seattle, WA) – AWS Big Data Meetup.
- April 28 – Webinar – Squeeze More Savings From Your AWS Reserved Instances.
- April 29 – Live Event (Singapore) – AWS Partner Summit.
- May 4 – Webinar – How to Empower Your End Users with Daas and Amazon WorkSpaces.
Help Wanted
Stay tuned for next week! In the meantime, follow me on Twitter and subscribe to the RSS feed.
- Jeff;
Amazon Offers a Solution to the Fire Tablet Deregistration Issue
Following the release of the new and improved Fire tablets, are multiple complaints from owners of the Fire 8.9, 8 and 6 where their devices spontaneously deregistered on their own which resulted to a complete wipe-out of its memory. A couple of days after the complaints came out, Amazon finally confirmed the issue … Continue reading Amazon Offers a Solution to the Fire Tablet Deregistration Issue 
Friday, April 22, 2016
AWS Webinars – April 2016
Our 2016 series of webinars continues with a strong set of 200-level topics in April. The webinars are free, but space is limited and you should sign up ahead of time if you would like to attend. Here's what we have on the calendar for the last week of April (all times are Pacific):
Tuesday, April 26
Are you ready to launch and connect to your first EC2 instance? Do you want to learn how to use Amazon Simple Storage Service (S3) to store and share files? Our getting started webinar will show you how to do both.
Webinar: Getting Started with AWS (9 – 10 AM).
Do you want to learn how to use Apache Spark to analyze real-time streams of data on an Amazon EMR cluster? Do you want to know how to use Spark as part of a system that includes Amazon DynamoDB, Amazon Redshift, Amazon Kinesis, and other big data tools? This webinar will show you how to use Spark to address common big data use cases.
Webinar: Best Practices for Apache Spark on AWS (10:30 – 11:30 AM).
Are you interested in running a commercial relational database in the cloud? Do you want to know more about best practices for running single and multiple database instances, or do you have questions about costs and licensing? Attend this webinar to learn more about Amazon RDS running Oracle.
Webinar: RDS for Oracle: Quick Provision, Easy to Manage, Reduced Cost (Noon – 1 PM).
Wednesday, April 27
In today's real-time world, going from raw data to insights as quickly as possible has become a must. Fortunately, a number of AWS tools can help you to capture, store, and analyze real-time streaming data. Attend this webinar to learn about Amazon Kinesis Streams, Lambda, and Spark Streaming on Amazon EMR.
Webinar: Getting Started with Real-Time Data Analytics on AWS (9 – 10 AM).
As you move your business and your applications to the cloud, you should also look at modernizing your development and deployment practices. For example, many AWS customers use tools like AWS CodePipeline and AWS CodeDeploy to implement continuous delivery. Attend this webinar to learn more about what this means and how to put it in to practice in your own organization.
Webinar: Getting Started with Continuous Delivery on AWS (10:30 – 11:30 AM).
Now that Amazon S3 is a decade old, we have a wealth of experience to share about the best ways to use it for backup, compliance, archiving, and many other purposes. This webinar will share best practices for keeping your data safe, and will also provide an overview of several different transfer services.
Webinar: S3 Best Practices: A Decade of Field Experience (Noon – 1 PM).
Thursday, April 28
AWS Lambda brings some new flexibility to the development and deployment process. When used in conjunction with AWS Storage Gateway, it can be used as the basis for an automated development workflow that easily supports distinct development, staging, and production environments. Attend this webinar to learn more.
Webinar: Continuous Delivery to AWS Lambda (9 AM – 10 AM).
Amazon Aurora is a MySQL-compatible database engine that can boost performance, reliability, and availability while reducing the total cost of ownership. Join this webinar to learn more about Aurora and to better understand how to migrate your existing on-premises or cloud-based databases to it.
Webinar: Migrating Your Databases to Amazon Aurora (10:30 – 11:30 AM).
Containers and microservices are both a natural fit for the cloud. Attend this webinar to learn more about the challenges that might arise and the best practices to address them.
Webinar: Running Microservices on Amazon ECS (Noon – 1 PM).
-Jeff;
Thursday, April 21, 2016
Amazon Offers New Colors for its $50 Fire Tablet
Are you bored of your plain, old black tablet? In the market for a new, budget-friendly e-reader? Then great news because Amazon just launched its upgraded Fire tablet with higher storage options and three new colors – blue, orange and pink. For only $49.99 (8gb) and $69.99 (16gb), you get to read your … Continue reading Amazon Offers New Colors for its $50 Fire Tablet 
Amazon EMR Update – Apache HBase 1.2 Is Now Available
Apache HBase is a distributed, scalable big data store designed to support tables with billions of rows and millions of columns. HBase runs on top of Hadoop and HDFS and can also be queried using MapReduce, Hive, and Pig jobs.
AWS customers use HBase for their ad tech, web analytics, and financial services workloads. They appreciate its scalability and the ease with which it handles time-series data.
HBase 1.2 on Amazon EMR
Today we are making version 1.2 of HBase available for use with Amazon EMR. Here are some of the most important and powerful features and benefits that you get when you run HBase:
Strongly Consistent Reads and Writes – When a writer returns, all of the readers will see the same value.
Scalability – Individual HBase tables can be comprised of billions of rows and millions of columns. HBase stores data in a sparse form in order to conserve space. You can use column families and column prefixes to organize your schemas and to indicate to HBase that the members of the family have a similar access pattern. You can also use timestamps and versioning to retain old versions of cells.
Backup to S3 – You can use the HBase Export Snapshot tool to backup your tables to Amazon S3. The backup operation is actually a MapReduce job and uses parallel processing to adeptly handle large tables.
Graphs And Timeseries – You can use HBase as the foundation for a more specialized data store. For example, you can use Titan for graph databases and OpenTSDB for time series.
Coprocessors – You can write custom business logic (similar to a trigger or a stored procedure) that runs within HBase and participates in query and update processing (read The How To of HBase Coprocessors to learn more).
You also get easy provisioning and scaling, access to a pre-configured installation of HDFS, and automatic node replacement for increased durability.
Getting Started with HBase
HBase 1.2 is available as part of Amazon EMR release 4.6. You can, as usual, launch it from the Amazon EMR Console, the Amazon EMR CLI, or through the Amazon EMR API. Here's the command that I used:
$ aws --region us-east-1 emr create-cluster \
--name "MyCluster" --release-label "emr-4.6.0" \
--instance-type m3.xlarge --instance-count 3 --use-default-roles \
--ec2-attributes KeyName=keys-jbarr-us-east \
--applications Name=Hadoop Name=Hue Name=HBase Name=HiveThis command assumes that the EMR_DefaultRole and EMR_EC2_DefaultRole IAM roles already exist. They are created automatically when you launch an EMR cluster from the Console (read about Create and Use Roles for Amazon EMR and Create and Use Roles with the AWS CLI to learn more).
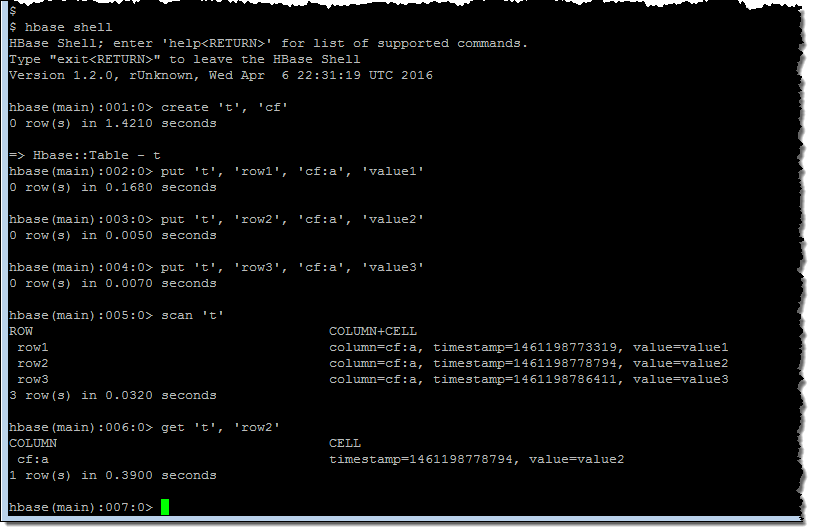
I found the master node's DNS on the Cluster Details page and SSH'ed in as user hadoop. Then I ran a couple of HBase shell commands:
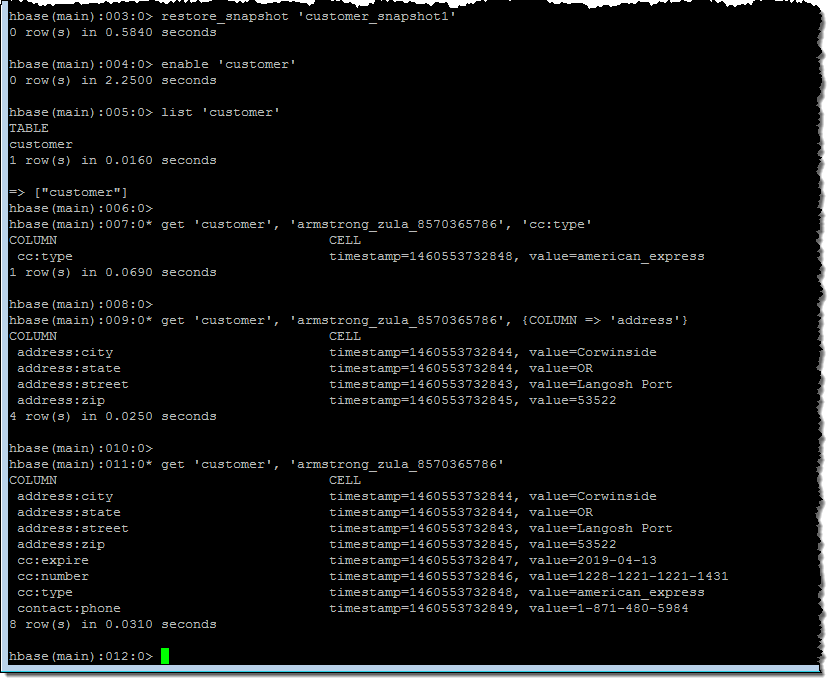
Following the directions in our new HBase Tutorial, I created a table called customer, restored a multi-million record snapshot from S3 into the table, and ran some simple queries:
Available Now
You can start using HBase 1.2 on Amazon EMR today. To learn more, read the Amazon EMR Documentation.
Jeff;
Wednesday, April 20, 2016
AWS Week in Review – April 11, 2016
Let's take a quick look at what happened in AWS-land last week:
New & Notable Open Source
- cfn-include implements a Fn::Include for CloudFormation templates.
- TumblessTemplates is a set of CloudFormation templates for quick setup of the Tumbless blogging platform.
- s3git is Git for cloud storage.
- s3_uploader is an S3 file uploader GUI written in Python.
- SSH2EC2 lets you connect to EC2 instances via tags and metadata.
- lambada is AWS Lambda for silly people.
- aws-iam-proxy is a proxy that signs requests with IAM credentials.
- hyperion is a Scala library and a set of abstractions for AWS Data Pipeline.
- dynq is a DynamoDB query library.
- cloud-custodian is a policy rules engine for AWS management.
New SlideShare Presentations
- AWS Summit (Chicago):
- Announcements for Mobile Developers.
- AWS Data Transfer Services.
- Containers and the Evolution of Computing.
- Getting Started with AWS IoT.
- Automating Security Operations on AWS.
- Getting Started with Amazon Enterprise Applications.
- Getting Started with Amazon EC2 and AWS Compute Services.
- Big Data Architectural Patterns and Best Practices on AWS.
- Security & Cloud Adoption for the Enterprise. Not If. When.
- Building and Realizing the Economic Case for the AWS Cloud.
- Building Your First Big Data Application on AWS.
- Building Your Practice on AWS.
- Getting Started with AWS Database Migration Service.
- Getting Started with Amazon Machine Learning.
- Women in Technology: Supporting Diversity in a Technical Workplace.
- DevOps on AWS: Deep Dive on Continuous Delivery and the AWS Developer Tools.
- Deep Dive on Microservices and Amazon ECS.
- Creating Your Virtual Data Center.
- AWS Application Discovery Service.
- Amazon WorkSpaces and Amazon WorkSpaces Application Manager.
- Amazon EBS Deep Dive.
- Deep Dive and Best Practices for Real-Time Streaming Applications.
- Deploying a Disaster Recovery Site on AWS.
- Deep Dive on Amazon S3.
- Deep Dive on Amazon Aurora.
- Another Day, Another Billion Packets.
- Getting Started with Amazon QuickSight.
- Deep Dive: Amazon DynamoDB.
- AWS for Startups.
- Deep Dive: EC2 Container Service.
- Amazon EC2 Masterclass.
- AWS in Financial Services.
- AWS Value Proposition.
- Modern BI in the Cloud with Tableau Server on Amazon EC2.
- Securing Gene Sequencing Data on AWS with Alert Logic.
- Agile BI in the Cloud.
New Customer Success Stories
- Airbnb.
- amaysim.
- AsiaInfo.
- Avira.
- Canon.
- e-Travel.
- Fugro Roames.
- Hello Inc.
- KKBOX.
- Rednun.
- Sage Human Capital.
- Thrive Market.
- V Air.
New YouTube Videos
- Introducing Amazon Inspector.
- Amazon Kinesis Firehose – Load Data into Amazon Elasticsearch Domains.
- Amazon S3 Transfer Acceleration.
- AWS Snowball – 80 TB Snowball Device.
- AWS Cloud Data Migration Services.
- AWS Elastic Beanstalk – Managed Platform Updates.
- Maximizing Your Organization's Potential with AWS.
- Are Your Cloud Workloads Secure?
- How to Set Up Amazon S3 Lifecycle Policies.
- Introducing New Amazon S3 Lifecycle Policies.
- 2016 AWS Public Sector Summit.
Upcoming Events
- AWS Partner Webinars – April.
- April 29 – Live Event (Singapore) – AWS Partner Summit.
- AWS Zombie Microservices Roadshow.
Help Wanted
Stay tuned for next week! In the meantime, follow me on Twitter and subscribe to the RSS feed.
- Jeff;
Need Medical Advice for your Child? Take it from Alexa.
Thanks to the latest update to Alexa-powered devices, you can now seek health advice from Boston Children's Hospital through the KidsMD skill that you need to activate using the Alexa App. “Our current focus is on providing educational information on common pediatric symptoms and guidance for at-home treatment,” Jared Hawkins, MMSc, PhD, and … Continue reading Need Medical Advice for your Child? Take it from Alexa. 
Tuesday, April 19, 2016
Is Amazon targeting Netflix?
Yesterday, we talked about the new Prime subscriptions from Amazon which include the stand-alone video streaming service for $8.99/month. Before the new services were launched, the only way to watch Prime videos was through the Prime Membership where you pay $99/year. Speculations say that Amazon is now targeting other video streaming services such … Continue reading Is Amazon targeting Netflix? 
AWS Device Farm Update – Remote Access to Devices for Interactive Testing
Last year I wrote about AWS Device Farm and told you how you can use it to Test Mobile Apps on Real Devices. As I described at the time, AWS Device Farm allows you to create a project, identify an application, configure a test, and then run the test against a variety of iOS and Android devices.
Remote Access to Devices
Today we are launching a new feature that provides you with remote access to devices (phones and tablets) for interactive testing. You simply open a new session on the desired device, wait (generally a minute or two) until the device is available, and then interact with the device via the AWS Management Console.
You can gesture, swipe, and interact with devices in real time directly through your web browser as if the device was on your desk or in your hand. This includes installing and running applications!
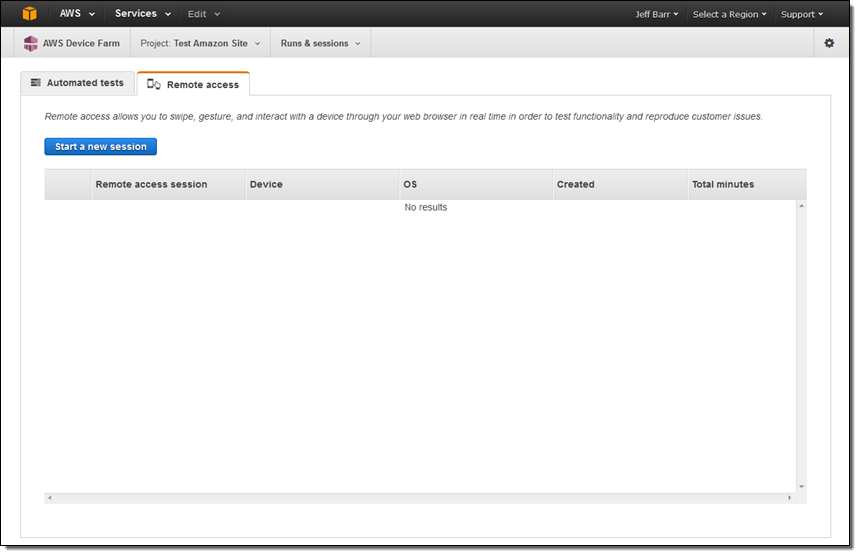
Here's a quick demo. I click on Start a new session to begin:
Then I search for a device of the desired type, including the desired OS version, select it, and name my session. I click on Confirm and start session to proceed:
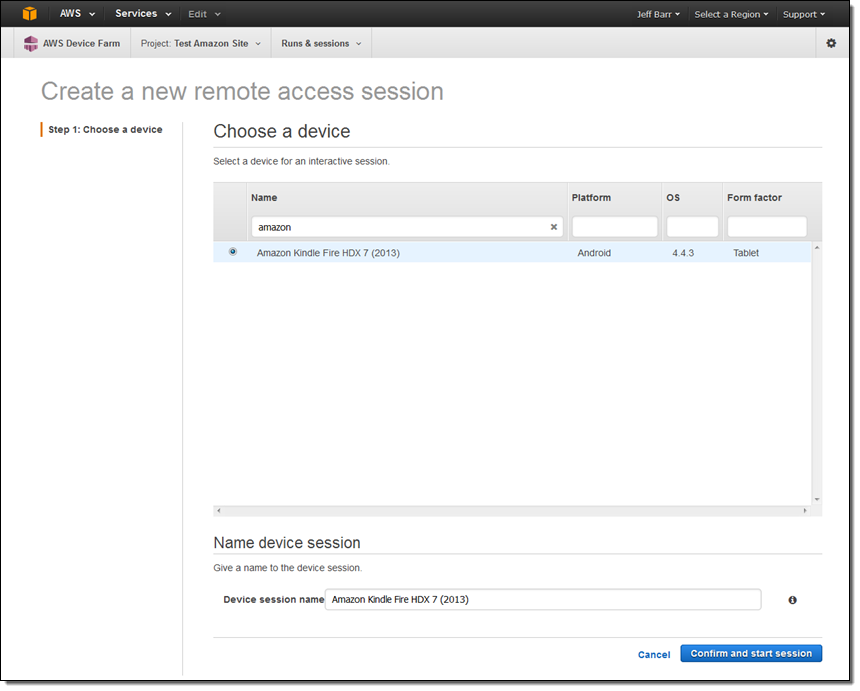
Then I wait for the device to become available (about 30 seconds in this case):
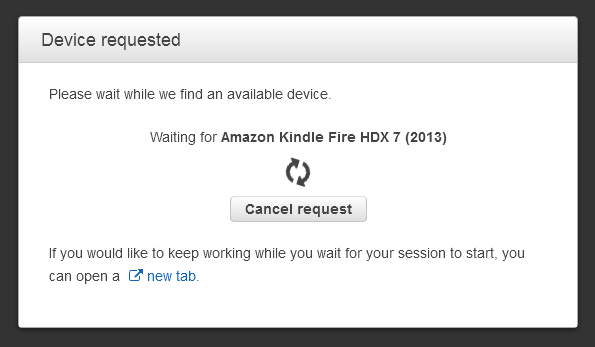
Once the device is available I can see the screen and access it through the Console:
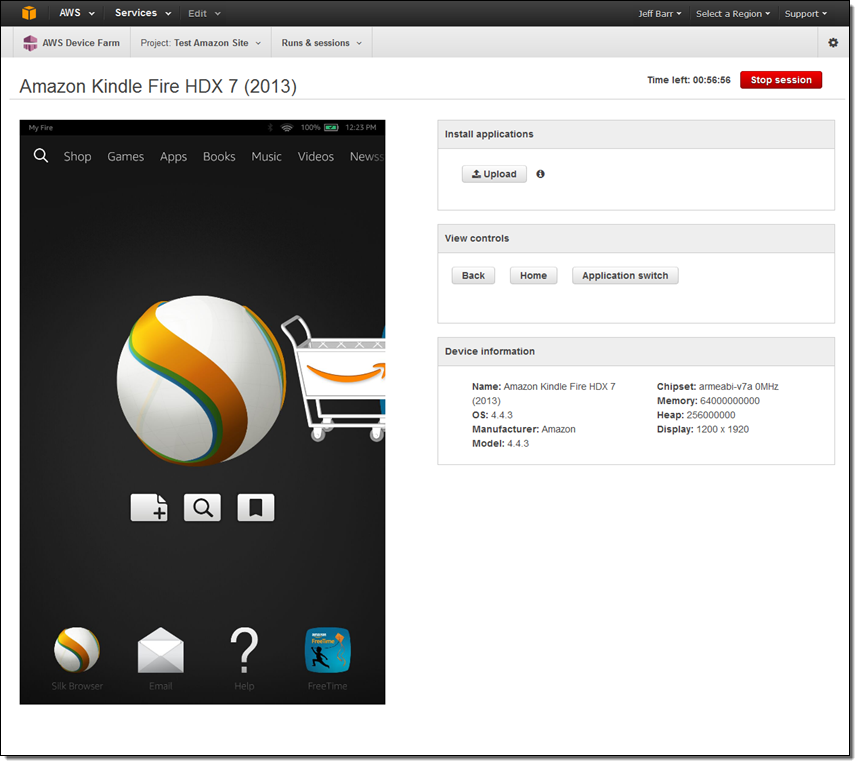
I can interact with the Kindle Fire using my mouse. Perhaps my app is not behaving as expected when the language is set to Latin American Spanish. I can change the Kindle Fire's settings with a couple of clicks:
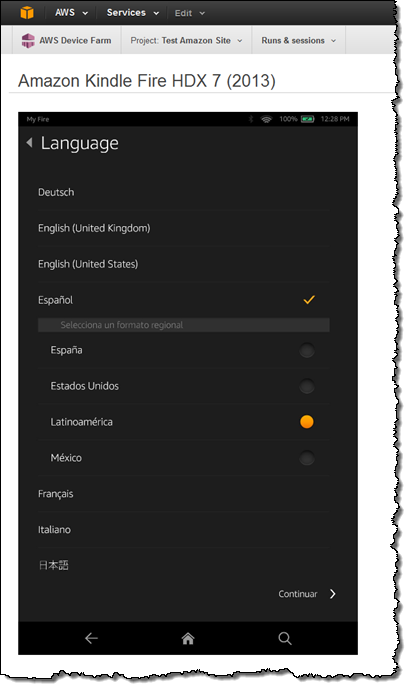
I can install my app on the Kindle Fire by clicking on Upload and choosing my APK.
My session can run for up to 60 minutes. After that time it will stop automatically.
Available Now
This new feature is available in beta form now, with a wide selection of Android phones and tablets. We will be adding iOS devices later this year, along with additional control over the device configuration and (virtual) location.
AWS Device Farm comes with a one-time free trial of 250 device minutes. After that you are charged $0.17 per device minute. Or you can pay $250 per slot per month for unmetered access (slots are the units of concurrent execution).
-Jeff;
Monday, April 18, 2016
New Prime Subscriptions on Amazon
Send to Kindle An Amazon Prime membership costs $99 for a year of free shipping, unlimited Prime Music/Video, free unlimited storage in Amazon Cloud drive and free ebooks each month. But for some, a year-long commitment can be scary. Thanks to the new Prime subscriptions that Amazon introduced, you can now enjoy the perks of … Continue reading New Prime Subscriptions on Amazon 
Sunday, April 17, 2016
An “all glass” iPhone in 2017?
In a new report issued by KGI Securities analyst Ming-Chi Kuo, it was predicted that Apple is ditching its aluminum unibody for a new “all glass” design with AMOLED display that will be possibly launched on September 2017. This total makeover is Apple's way to differentiate itself from competitors that are all using aluminum … Continue reading An “all glass” iPhone in 2017? 
Thursday, April 14, 2016
Update your iDevices ASAP!
If you own an iPad or iPhone that runs an iOS older than 9.3.1, you should do a software update immediately. Security researchers revealed that it is possible to brick an iPad through Wi-Fi connection. This permanent bug will leave your device frozen till your battery runs out and since there is “no … Continue reading Update your iDevices ASAP! 
Subscribe to:
Comments (Atom)