Thursday, March 31, 2016
New Brands for Your Amazon Dash Button
A year after the announcement of the Dash Button, new big-name brands were added to this Amazon Prime-exclusive program. There are currently more than a hundred Amazon Dash Buttons available on the e-commerce site for only $4.99 each. The idea behind this program is for users to conveniently re-order their favorite products with … Continue reading New Brands for Your Amazon Dash Button 
New Brands for Your Amazon Dash Button
A year after the announcement of the Dash Button, new big-name brands were added to this Amazon Prime-exclusive program. There are currently more than a hundred Amazon Dash Buttons available on the e-commerce site for only $4.99 each. The idea behind this program is for users to conveniently re-order their favorite products with … Continue reading New Brands for Your Amazon Dash Button
Wednesday, March 30, 2016
Amazon Bans Dangerous USB-C Cables
Send to Kindle Amazon added another item to its Restricted Products list for third-party sellers – any USB-C cable or adapter product that is not compliant with the “USB Implementers Forum Inc.” standard specifications. This is to protect potential buyers from the dangers of using low quality cables that can fry your computers, smartphones, tablets … Continue reading Amazon Bans Dangerous USB-C Cables 
Experiment that Discovered the Higgs Boson Uses AWS to Probe Nature
My colleague Sanjay Padhi is part of the AWS Scientific Computing team. He wrote the guest post below to share the story of how AWS provided computational resources that aided in an important scientific discovery.
-Jeff;
The Higgs boson (sometimes referred to as the God Particle), responsible for providing insight into the origin of mass, was discovered in 2012 by the world's largest experiments, ATLAS and CMS, at the Large Hadron Collider (LHC) at CERN in Geneva, Switzerland. The theorists behind this discovery were awarded the 2013 Nobel Prize in Physics.
Deep underground on the border between France and Switzerland, the LHC is the world's largest (17 miles in circumference) and highest-energy particle accelerator. It explores nature on smaller scales than any human invention has ever explored before.
From Experiment to Raw Data
The high energy particle collisions turn mass in to energy, which then turns back in to mass, creating new particles that are observed in the CMS detector. This detector is 69 feet long, 49 feet wide and 49 feet high, and sits in a cavern 328 feet underground near the village of Cessy in France. The raw data from the CMS is recorded every 25 nanoseconds at a rate of approximately 1 petabyte per second.
After online and offline processing of the raw data at the CERN Tier 0 data center, the datasets are distributed to 7 large Tier 1 data centers across the world within 48 hours, ready for further processing and analysis by scientists (the CMS collaboration, one of the largest in the world, consists of more than 3,000 participating members from over 180 institutes and universities in 43 countries).
Processing at Fermilab
Fermilab is one of 16 National Laboratories operated by the United States Department of Energy. Located just outside Batavia Illinois, Fermilab serves as one of the Tier 1 data centers for Cern's CMS experiment.
With the increase in LHC collision energy last year, the demand for data assimilation, event simulations, and large-scale computing increased as well. With this increase came a desire to maximize cost efficiency by dynamically provisioning resources on an as-needed basis.
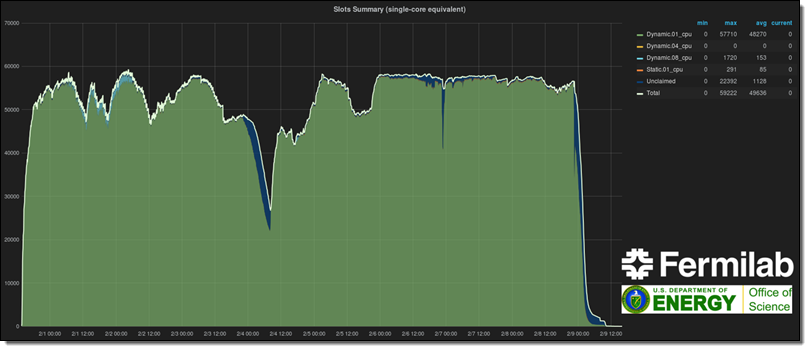
In order to address this issue, the Fermilab Scientific Computing Division launched the HEP (High Energy Physics) Cloud project in June of 2015. They planned to develop a virtual facility that would provide a common interface to access a variety of computing resources including commercial clouds. Using AWS, the HEP Cloud project successfully demonstrated the ability to add 58,000 cores elastically to their on-premises facility for the CMS experiment.
The image below depicts one of the simulations that was run on AWS. It shows how the collision of two protons creates energy that then becomes new particles.

The additional 58,000 cores represents a 4x increase in Fermilab's computational capacity, all of which is dedicated to the CMS experiment in order to generate and reconstruct Monte Carlo simulation events. More than 500 million events were fully simulated in 10 days using 2.9 million jobs. Without help from AWS, this job would have taken 6 weeks to complete using the on-premises compute resources at Fermilab.
This simulation was done in preparation for one of the major high energy physics international conferences, Recontres de Moriond. Physicists across the world will use these simulations to probe nature in detail and will share their findings with their international colleagues during the conference.
Saving Money with HEP Cloud
The HEP Cloud project aims to minimize the costs of computation. The R&D and demonstration effort was supported by an award from the AWS Cloud Credit for Research.
HEP Cloud's decision engine, the brain of the facility, has several duties. It oversees EC2 Spot Market price fluctuations using tools and techniques provided by Amazon's Spot team, initializes Amazon EC2 instances using HTCondor, tracks the DNS names of the instances using Amazon Route 53 , and makes use of AWS CloudFormation templates for infrastructure as a code.
While on the road to success, the project team had to overcome several challenges, ranging from fine-tuning configurations to optimizing their use of Amazon S3 and other resources. For example, they devised a strategy to distribute the auxiliary data across multiple AWS Regions in order to minimize storage costs and data-access latency.
Automatic Scaling into AWS
The figure below shows elastic, automatic expansion of Fermilab's Computing Facility into the AWS Cloud using Spot instances for CMS workflows. Monitoring of the resources was done using open source software provided by Grafana with custom modifications provided by the HEP Cloud.
Panagiotis Spentzouris (head of the Scientific Computing Division at Fermilab), told me:
 Modern HEP experiments require massive computing resources in irregular cycles, so it is imperative for the success of our program that our computing facilities can rapidly expand and contract resources to match demand. Using commercial clouds is an important ingredient for achieving this goal, and our work with AWS on the CMS experiment's workloads though HEPCloud was a great success in demonstrating the value of this approach.
Modern HEP experiments require massive computing resources in irregular cycles, so it is imperative for the success of our program that our computing facilities can rapidly expand and contract resources to match demand. Using commercial clouds is an important ingredient for achieving this goal, and our work with AWS on the CMS experiment's workloads though HEPCloud was a great success in demonstrating the value of this approach.
I hope that you enjoyed this brief insight into the ways in which AWS is helping to explore the frontiers of physics!
- Sanjay Padhi, Ph.D, AWS Scientific Computing



Amazon Bans Dangerous USB-C Cables
Send to Kindle Amazon added another item to its Restricted Products list for third-party sellers – any USB-C cable or adapter product that is not compliant with the “USB Implementers Forum Inc.” standard specifications. This is to protect potential buyers from the dangers of using low quality cables that can fry your computers, smartphones, tablets … Continue reading Amazon Bans Dangerous USB-C Cables
Experiment that Discovered the Higgs Boson Uses AWS to Probe Nature
My colleague Sanjay Padhi is part of the AWS Scientific Computing team. He wrote the guest post below to share the story of how AWS provided computational resources that aided in an important scientific discovery.
-Jeff;
The Higgs boson (sometimes referred to as the God Particle), responsible for providing insight into the origin of mass, was discovered in 2012 by the world's largest experiments, ATLAS and CMS, at the Large Hadron Collider (LHC) at CERN in Geneva, Switzerland. The theorists behind this discovery were awarded the 2013 Nobel Prize in Physics.
Deep underground on the border between France and Switzerland, the LHC is the world's largest (17 miles in circumference) and highest-energy particle accelerator. It explores nature on smaller scales than any human invention has ever explored before.
From Experiment to Raw Data
The high energy particle collisions turn mass in to energy, which then turns back in to mass, creating new particles that are observed in the CMS detector. This detector is 69 feet long, 49 feet wide and 49 feet high, and sits in a cavern 328 feet underground near the village of Cessy in France. The raw data from the CMS is recorded every 25 nanoseconds at a rate of approximately 1 petabyte per second.
After online and offline processing of the raw data at the CERN Tier 0 data center, the datasets are distributed to 7 large Tier 1 data centers across the world within 48 hours, ready for further processing and analysis by scientists (the CMS collaboration, one of the largest in the world, consists of more than 3,000 participating members from over 180 institutes and universities in 43 countries).
Processing at Fermilab
Fermilab is one of 16 National Laboratories operated by the United States Department of Energy. Located just outside Batavia Illinois, Fermilab serves as one of the Tier 1 data centers for Cern's CMS experiment.
With the increase in LHC collision energy last year, the demand for data assimilation, event simulations, and large-scale computing increased as well. With this increase came a desire to maximize cost efficiency by dynamically provisioning resources on an as-needed basis.
In order to address this issue, the Fermilab Scientific Computing Division launched the HEP (High Energy Physics) Cloud project in June of 2015. They planned to develop a virtual facility that would provide a common interface to access a variety of computing resources including commercial clouds. Using AWS, the HEP Cloud project successfully demonstrated the ability to add 58,000 cores elastically to their on-premises facility for the CMS experiment.
The image below depicts one of the simulations that was run on AWS. It shows how the collision of two protons creates energy that then becomes new particles.
The additional 58,000 cores represents a 4x increase in Fermilab's computational capacity, all of which is dedicated to the CMS experiment in order to generate and reconstruct Monte Carlo simulation events. More than 500 million events were fully simulated in 10 days using 2.9 million jobs. Without help from AWS, this job would have taken 6 weeks to complete using the on-premises compute resources at Fermilab.
This simulation was done in preparation for one of the major high energy physics international conferences, Recontres de Moriond. Physicists across the world will use these simulations to probe nature in detail and will share their findings with their international colleagues during the conference.
Saving Money with HEP Cloud
The HEP Cloud project aims to minimize the costs of computation. The R&D and demonstration effort was supported by an award from the AWS Cloud Credit for Research.
HEP Cloud's decision engine, the brain of the facility, has several duties. It oversees EC2 Spot Market price fluctuations using tools and techniques provided by Amazon's Spot team, initializes Amazon EC2 instances using HTCondor, tracks the DNS names of the instances using Amazon Route 53 , and makes use of AWS CloudFormation templates for infrastructure as a code.
While on the road to success, the project team had to overcome several challenges, ranging from fine-tuning configurations to optimizing their use of Amazon S3 and other resources. For example, they devised a strategy to distribute the auxiliary data across multiple AWS Regions in order to minimize storage costs and data-access latency.
Automatic Scaling into AWS
The figure below shows elastic, automatic expansion of Fermilab's Computing Facility into the AWS Cloud using Spot instances for CMS workflows. Monitoring of the resources was done using open source software provided by Grafana with custom modifications provided by the HEP Cloud.
Panagiotis Spentzouris (head of the Scientific Computing Division at Fermilab), told me:
Modern HEP experiments require massive computing resources in irregular cycles, so it is imperative for the success of our program that our computing facilities can rapidly expand and contract resources to match demand. Using commercial clouds is an important ingredient for achieving this goal, and our work with AWS on the CMS experiment's workloads though HEPCloud was a great success in demonstrating the value of this approach.
I hope that you enjoyed this brief insight into the ways in which AWS is helping to explore the frontiers of physics!
- Sanjay Padhi, Ph.D, AWS Scientific Computing
Tuesday, March 29, 2016
A 2nd Gen Dash Button with Bluetooth is Coming
The Amazon Dash Button has been around for a year alread and now, the 2nd Generation might just be launched as a replacement. According to a report published on the FCC website, it appeared that an unnamed gadget was listed which looks exactly like the existing Dash Button. This was discovered by Dave … Continue reading A 2nd Gen Dash Button with Bluetooth is Coming 
New – Change Sets for AWS CloudFormation
AWS CloudFormation lets you create, manage, and update a collection of AWS resources (a “stack”) in a controlled, predictable manner. Every day, customers use CloudFormation to perform hundreds of thousands of updates to the stacks that support their production workloads. They define an initial template and then revise it as their requirements change.
This model, commonly known as infrastructure as code, gives developers, architects, and operations teams detailed control of the provisioning and configuration of their AWS resources. This detailed level of control and accountability is one of the most visible benefits that you get when you use CloudFormation. However, there are several others that are less visible but equally important:
Consistency – The CloudFormation team works with the AWS teams to make sure that newly added resource models have consistent semantics for creating, updating, and deleting resources. They take care to account for retries, idempotency, and management of related resources such as KMS keys for encrypting EBS or RDS volumes.
Stability – In any distributed system, issues related to eventual consistency often arise and must be dealt with. CloudFormation is intimately aware of these issues and automatically waits for any necessary propagation to complete before proceeding. In many cases they work with the service teams to ensure that their APIs and success signals are properly tuned for use with CloudFormation.
Uniformity – CloudFormation will choose between in-place updates and resource replacement when you make updates to your stacks.
All of this work takes time, and some of it cannot be completely tested until the relevant services have been launched or updated.
Improved Support for Updates
As I mentioned earlier, many AWS customers use CloudFormation to manage updates to their production stacks. They edit their existing template (or create a new one) and then use CloudFormation's Update Stack operation to activate the changes.
Many of our customers have asked us for additional insight into the changes that CloudFormation is planning to perform when it updates a stack in accord with the more recent template and/or parameter values. They want to be able to preview the changes, verify that they are in line with their expectations, and proceed with the update.
In order to support this important CloudFormation use case, we are introducing the concept of a change set. You create a change set by submitting changes against the stack you want to update. CloudFormation compares the stack to the new template and/or parameter values and produces a change set that you can review and then choose to apply (execute).
In addition to additional insight into potential changes, this new model also opens the door to additional control over updates. You can use IAM to control access to specific CloudFormation functions such as UpdateStack, CreateChangeSet, DescribeChangeSet, and ExecuteChangeSet. You could allow a large group developers to create and preview change sets, and restrict execution to a smaller and more experienced group. With some additional automation, you could raise alerts or seek additional approvals for changes to key resources such as database servers or networks.
Using Change Sets
Let's walk through the steps involved in working with change sets. As usual, you can get to the same functions using the AWS Command Line Interface (CLI), AWS Tools for Windows PowerShell, and the CloudFormation API.
I started by creating a stack that runs a LAMP stack on a single EC2 instance. Here are the resources that it created:
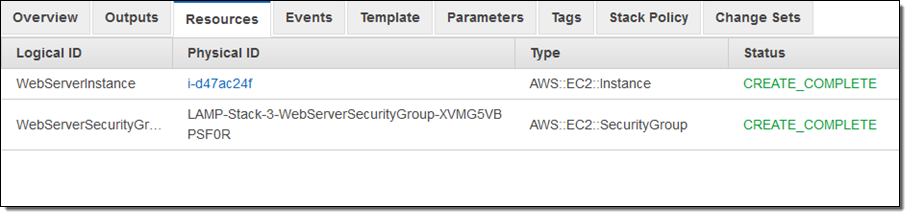
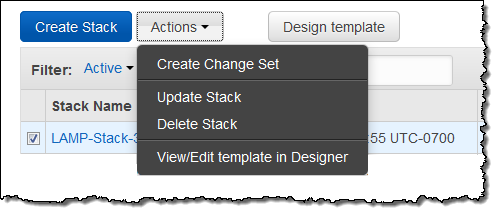
Then I decided to step up to a more complex architecture. One of my colleagues shared a suitable template with me. Using the “trust but verify” model, I created a change set in order to see what would happen were I to use the template. I clicked on Create Change Set:
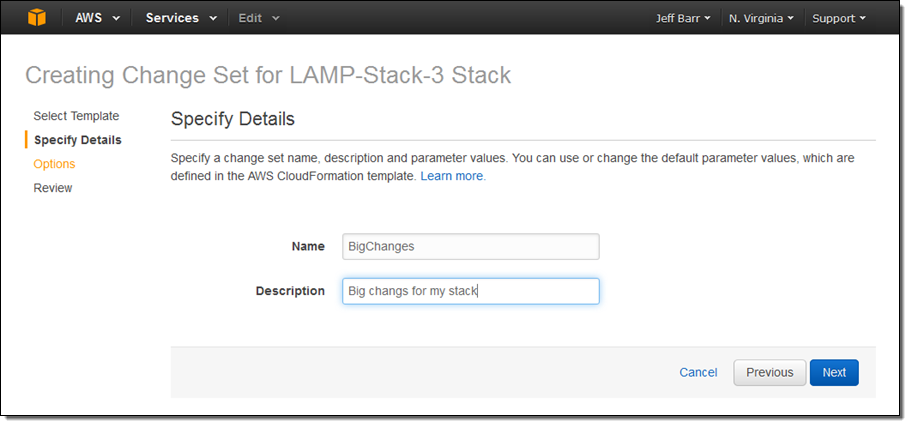
Then I uploaded the new template and assigned a name to the change set. If the template made use of parameters, I could have entered values for them at this point.
At this point I had the option to modify the existing tags and to add new ones. I also had the option to set up advanced options for the stack (none of these will apply until I actually execute the change set, of course):
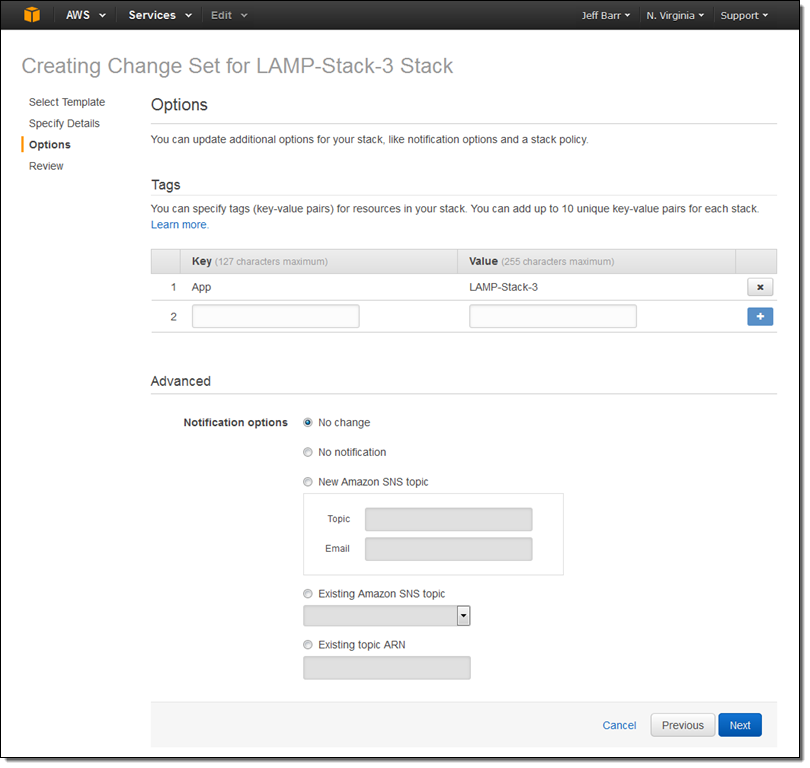
After another click or two to confirm my intent, the console analyzed the template, checks the results against the stack, and displayed the list of changes:
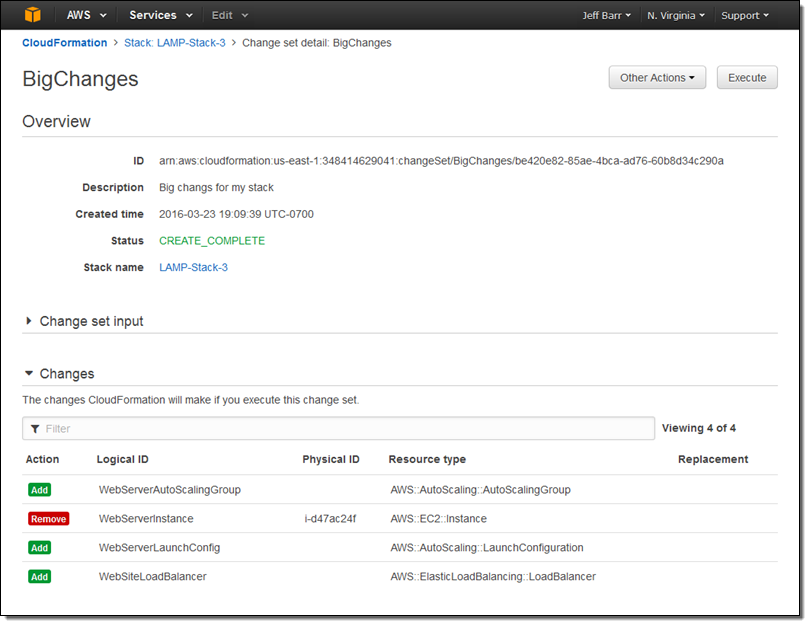
At this point I can click on Execute to effect the changes. I can also leave the change set as-is, or create several others in order to explore some alternate paths forward. When I am ready to go, I can locate the change set and execute it:
CloudFormation springs to action and implements the changes per the change set:
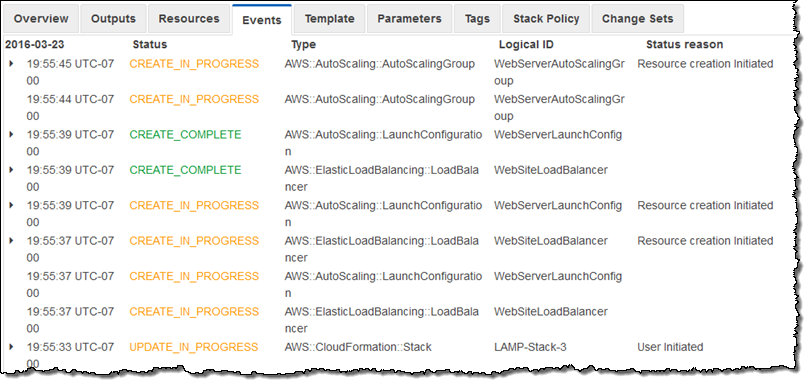
A few minutes later my new stack configuration was in place and fully operational:
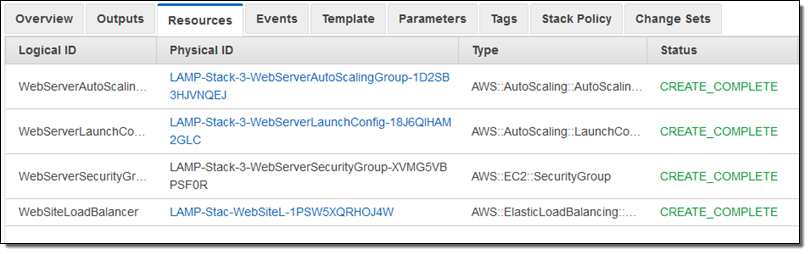
And there you have it! As I mentioned earlier, I can create and inspect multiple change sets before choosing the one that I would like to execute. When I do this, the other change sets are no longer meaningful and are discarded.
Managing Rollbacks
If a stack update fails, CloudFormation does its best to put things back the way there were before the update. The rollback operation can fail on occasion; in many cases this is due to a change that was made outside of CloudFormation's purview. We recently launched a new option that gives you additional control over what happens next. To learn more about this option, read Continue Rolling Back an Update for AWS CloudFormation stacks in the UPDATE_ROLLBACK_FAILED state.
Available Now
This functionality is available now and you can start using it today!
Jeff;
A 2nd Gen Dash Button with Bluetooth is Coming
The Amazon Dash Button has been around for a year alread and now, the 2nd Generation might just be launched as a replacement. According to a report published on the FCC website, it appeared that an unnamed gadget was listed which looks exactly like the existing Dash Button. This was discovered by Dave … Continue reading A 2nd Gen Dash Button with Bluetooth is Coming
New – Change Sets for AWS CloudFormation
AWS CloudFormation lets you create, manage, and update a collection of AWS resources (a “stack”) in a controlled, predictable manner. Every day, customers use CloudFormation to perform hundreds of thousands of updates to the stacks that support their production workloads. They define an initial template and then revise it as their requirements change.
This model, commonly known as infrastructure as code, gives developers, architects, and operations teams detailed control of the provisioning and configuration of their AWS resources. This detailed level of control and accountability is one of the most visible benefits that you get when you use CloudFormation. However, there are several others that are less visible but equally important:
Consistency – The CloudFormation team works with the AWS teams to make sure that newly added resource models have consistent semantics for creating, updating, and deleting resources. They take care to account for retries, idempotency, and management of related resources such as KMS keys for encrypting EBS or RDS volumes.
Stability – In any distributed system, issues related to eventual consistency often arise and must be dealt with. CloudFormation is intimately aware of these issues and automatically waits for any necessary propagation to complete before proceeding. In many cases they work with the service teams to ensure that their APIs and success signals are properly tuned for use with CloudFormation.
Uniformity – CloudFormation will choose between in-place updates and resource replacement when you make updates to your stacks.
All of this work takes time, and some of it cannot be completely tested until the relevant services have been launched or updated.
Improved Support for Updates
As I mentioned earlier, many AWS customers use CloudFormation to manage updates to their production stacks. They edit their existing template (or create a new one) and then use CloudFormation's Update Stack operation to activate the changes.
Many of our customers have asked us for additional insight into the changes that CloudFormation is planning to perform when it updates a stack in accord with the more recent template and/or parameter values. They want to be able to preview the changes, verify that they are in line with their expectations, and proceed with the update.
In order to support this important CloudFormation use case, we are introducing the concept of a change set. You create a change set by submitting changes against the stack you want to update. CloudFormation compares the stack to the new template and/or parameter values and produces a change set that you can review and then choose to apply (execute).
In addition to additional insight into potential changes, this new model also opens the door to additional control over updates. You can use IAM to control access to specific CloudFormation functions such as UpdateStack, CreateChangeSet, DescribeChangeSet, and ExecuteChangeSet. You could allow a large group developers to create and preview change sets, and restrict execution to a smaller and more experienced group. With some additional automation, you could raise alerts or seek additional approvals for changes to key resources such as database servers or networks.
Using Change Sets
Let's walk through the steps involved in working with change sets. As usual, you can get to the same functions using the AWS Command Line Interface (CLI), AWS Tools for Windows PowerShell, and the CloudFormation API.
I started by creating a stack that runs a LAMP stack on a single EC2 instance. Here are the resources that it created:
Then I decided to step up to a more complex architecture. One of my colleagues shared a suitable template with me. Using the “trust but verify” model, I created a change set in order to see what would happen were I to use the template. I clicked on Create Change Set:
Then I uploaded the new template and assigned a name to the change set. If the template made use of parameters, I could have entered values for them at this point.
At this point I had the option to modify the existing tags and to add new ones. I also had the option to set up advanced options for the stack (none of these will apply until I actually execute the change set, of course):
After another click or two to confirm my intent, the console analyzed the template, checks the results against the stack, and displayed the list of changes:
At this point I can click on Execute to effect the changes. I can also leave the change set as-is, or create several others in order to explore some alternate paths forward. When I am ready to go, I can locate the change set and execute it:
CloudFormation springs to action and implements the changes per the change set:
A few minutes later my new stack configuration was in place and fully operational:
And there you have it! As I mentioned earlier, I can create and inspect multiple change sets before choosing the one that I would like to execute. When I do this, the other change sets are no longer meaningful and are discarded.
Managing Rollbacks
If a stack update fails, CloudFormation does its best to put things back the way there were before the update. The rollback operation can fail on occasion; in many cases this is due to a change that was made outside of CloudFormation's purview. We recently launched a new option that gives you additional control over what happens next. To learn more about this option, read Continue Rolling Back an Update for AWS CloudFormation stacks in the UPDATE_ROLLBACK_FAILED state.
Available Now
This functionality is available now and you can start using it today!
Jeff;
Monday, March 28, 2016
An Alexa Competitor from Google?
Amazon’s Echo, Dot and Tap, have been really popular in a lot of households these days – thanks to their virtual assistant, Alexa, for its impressive skills and capabilities. From ordering you a pizza from Domino’s to getting you an Uber – the list goes on and on. Just a few days ago, … Continue reading An Alexa Competitor from Google? 
An Alexa Competitor from Google?
Amazon’s Echo, Dot and Tap, have been really popular in a lot of households these days – thanks to their virtual assistant, Alexa, for its impressive skills and capabilities. From ordering you a pizza from Domino’s to getting you an Uber – the list goes on and on. Just a few days ago, … Continue reading An Alexa Competitor from Google?
Sunday, March 27, 2016
Gear Up for Your Next Outdoor Adventure with these $1-Dollar GoPro Accessories
When you purchase a GoPro, it doesn’t really come with accessories unless you buy the ones that come in a bundle. So if you only own a GoPro or a compatible action cam, then get your hands on these deals where you can own every accessory for just a dollar per piece. Kit number one … Continue reading Gear Up for Your Next Outdoor Adventure with these $1-Dollar GoPro Accessories 
Thursday, March 24, 2016
ElastiCache for Redis Update – Upgrade Engines and Scale Up
Amazon ElastiCache makes it easy for you to deploy, operate, and scale an in-memory database in the cloud. As you may already know, ElastiCache supports the Memcached and Redis engines.
More Power for Redis
Today we are launching an ElastiCache update that provides you with additional control over your Redis-based ElastiCache clusters. You can now scale up to a larger node type while ElastiCache preserves (on a best-effort basis) your stored information. While ElastiCache for Redis has always allowed you to upgrade the engine version, you can now do so while preserving the stored information. You can apply both changes immediately or during the cluster’s maintenance window.
Behind the scenes, ElastiCache for Redis uses several different strategies to scale up and to upgrade engines. Scaling is based on Redis replication. Engine upgrades use a foreground snapshot (SAVE) when Multi-AZ is turned off, and replication followed by a DNS switch when it is on.
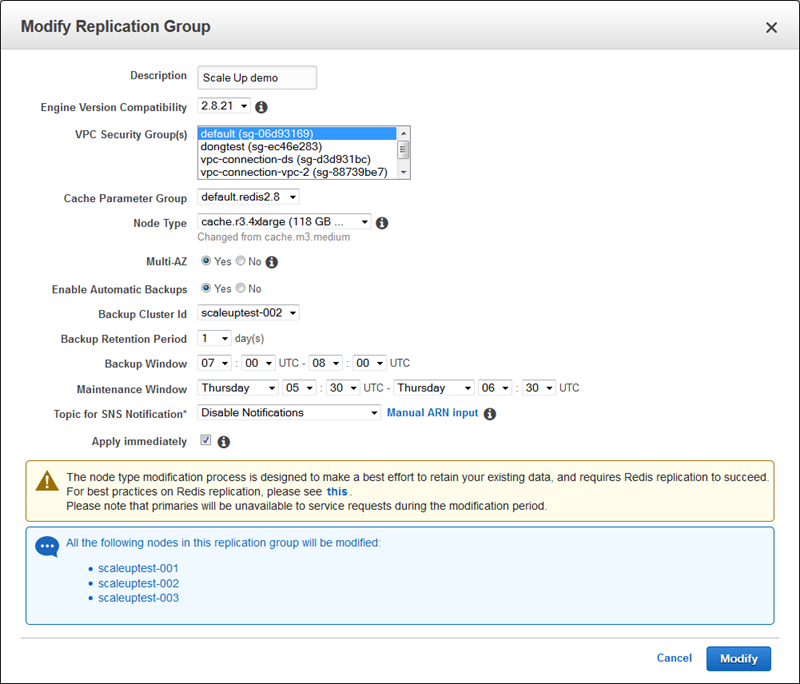
To scale up to a larger node type, simply select the Cache Cluster in the AWS Management Console and click on Modify. Then select the new Node Type, decide if you want to apply the change immediately, and click on Modify to proceed:
Similarly, to upgrade to a newer version of the Redis engine, select the new version and click on Modify:
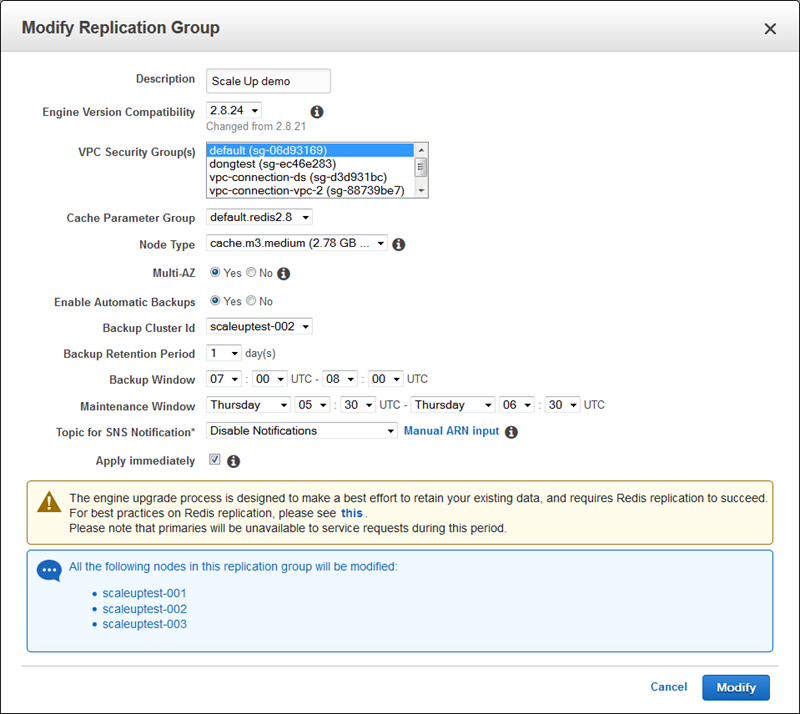
I would like to take this opportunity to encourage you to upgrade to the engine that is compatible with version 2.8.24 of Redis. This version contains a number of fixes and enhancements to Redis’ stability and robustness (some contributed by the ElastiCache team; see the What’s New for more information).
You can, as always, accomplish the same operations by way of the ElastiCache API. Here are some quick examples in PHP (via the AWS SDK for PHP):
// Scale to larger node size
$res = $client->modifyCacheCluster(['CacheNodeType' => 'cache.r3.4xlarge',
'ApplyImmediately' => true]);
// Upgrade engine version
$res = $client->modifyCacheCluster(['EngineVersion' => '2.8.24',
'ApplyImmediately' => true]);
// Do both at once
$res = $client->modifyCacheCluster(['CacheNodeType' => 'cache.r3.4xlarge',
'EngineVersion' => '2.8.24',
'ApplyImmediately' => true]);
In all three of these examples, the ApplyImmediately parameter indicates that the changes will be made right away rather than during the maintenance window.
To learn more, read Scaling Your Redis Cluster.
Available Now
This feature is available now and you can start using it today!
Jeff;
Subscribe to:
Comments (Atom)