Amazon EMR allows you to quickly and cost-effectively process vast amounts of data. Since the 2009 launch, we have added many new features and support for an ever-increasing roster of applications from the Hadoop ecosystem. Here are a few of the additions that we have made this year:
- April – Support for Apache HBase 1.2 (EMR 4.6).
- March – Support for Sqoop, HCatalog, Java 8, and more (EMR 4.4).
- February – Support for EBS volumes, M4 instances, and C4 instances.
- January – Support for Apache Spark, with updates to other applications.
Today we are pushing forward once again, with new support for Apache Tez (dataflow-driven data processing task orchestration) and Apache Phoenix (fast SQL for OLTP and operational analytics), along with updates to several of the existing apps. In order to make use of these new and/or updated applications, you will need to launch a cluster that runs release 4.7.0 of Amazon EMR.
New – Apache Tez (0.8.3)
Tez runs on top of Apache Hadoop YARN. Tez provides you with a set of dataflow definition APIs that allow you to define a DAG (Directed Acyclic Graph) of data processing tasks. Tez can be faster than Hadoop MapReduce, and can be used with both Hive and Pig. To learn more, read the EMR Release Guide. The Tez UI includes a graphical view of the DAG:
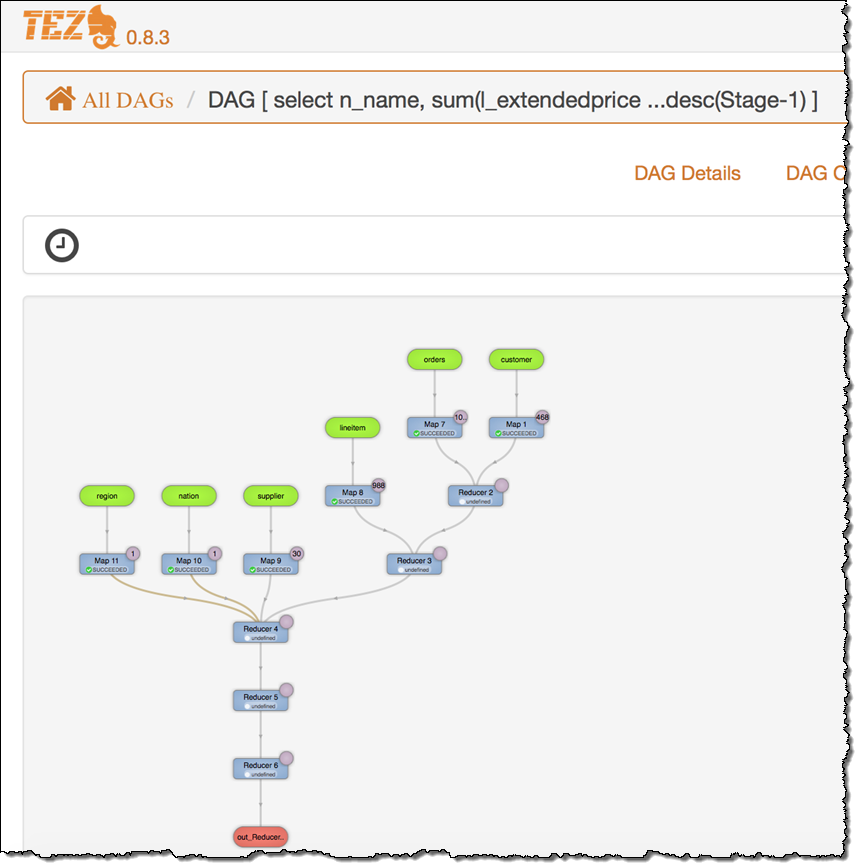
The UI also displays detailed information about each DAG:
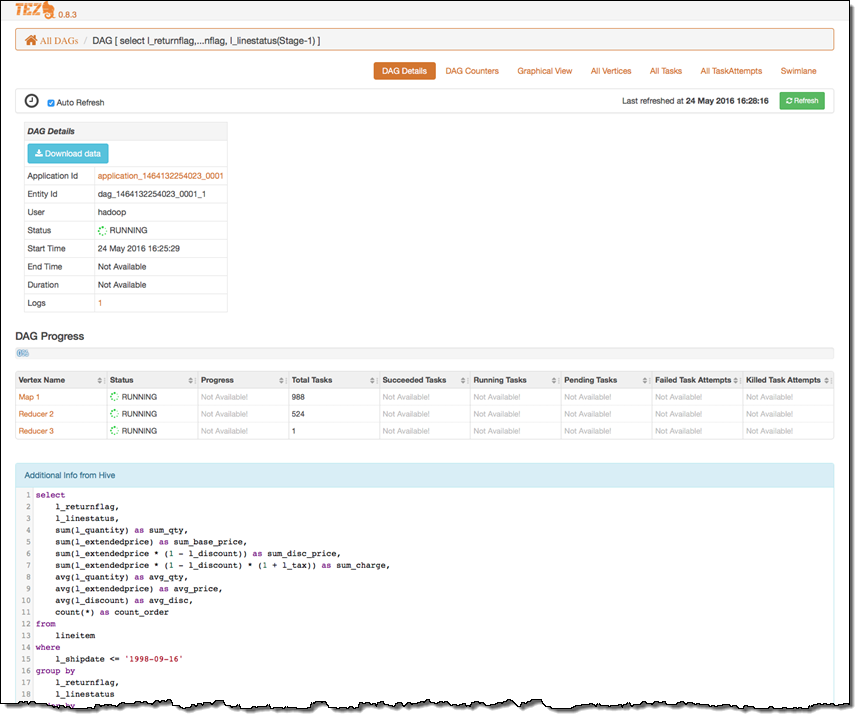
New – Apache Phoenix (4.7.0)
Phoenix uses HBase (another member of the Hadoop ecosystem) as its datastore. You can connect to Phoenix using a JDBC driver included on the cluster or from other applications that are running on or off of the cluster. Either way, you get access to fast, low-latency SQL with full ACID transaction capabilities. Your SQL queries are compiled into a series of HBase scans, the scans are run in parallel, and the results are aggregated to produce the result set. To learn more, read the Phoenix Quick Start Guide or review the Apache Phoenix Overview Presentation.
Updated Applications
We have also updated the following applications:
- HBase 1.2.1 – HBase provides low-latency, random access to massive datasets. The new version includes some bug fixes.
- Mahout 0.12.0 – Mahout provides scalable machine learning and data mining. The new version includes a large set of math and statistics features.
- Presto 0.147 – Presto is a distributed SQL query engine designed for large data sets. The new version adds features and fixes bugs.
Amazon Redshift JDBC Driver
You can use the new Redshift JDBC driver to allow applications running on your EMR clusters to access and update data stored in your Redshift clusters. Two versions of the driver are included on your cluster:
- JDBC 4.0-compatible –
/usr/share/aws/redshift/jdbc/RedshiftJDBC4.jar. - JDBC 4.1-compatible –
/usr/share/aws/redshift/jdbc/RedshiftJDBC41.jar.
To start using the new and applications, simply launch a new EMR cluster, and select release 4.7.0 along with the desired set of applications.
-Jeff;



No comments:
Post a Comment