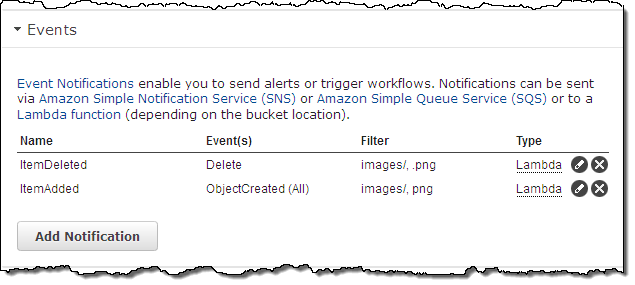
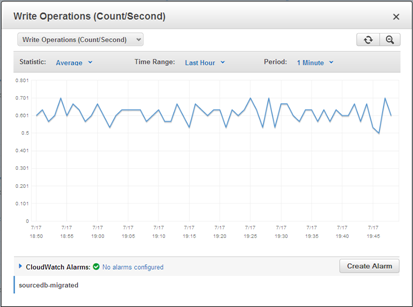
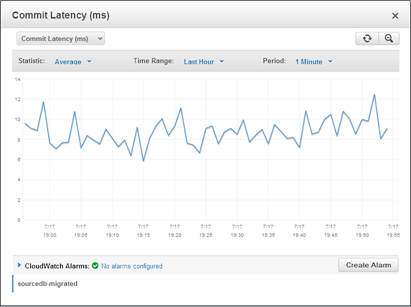
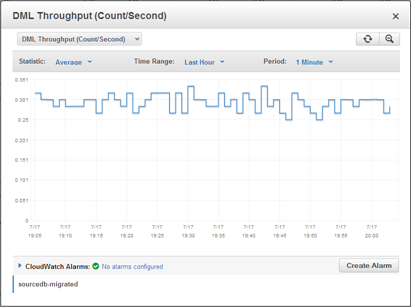
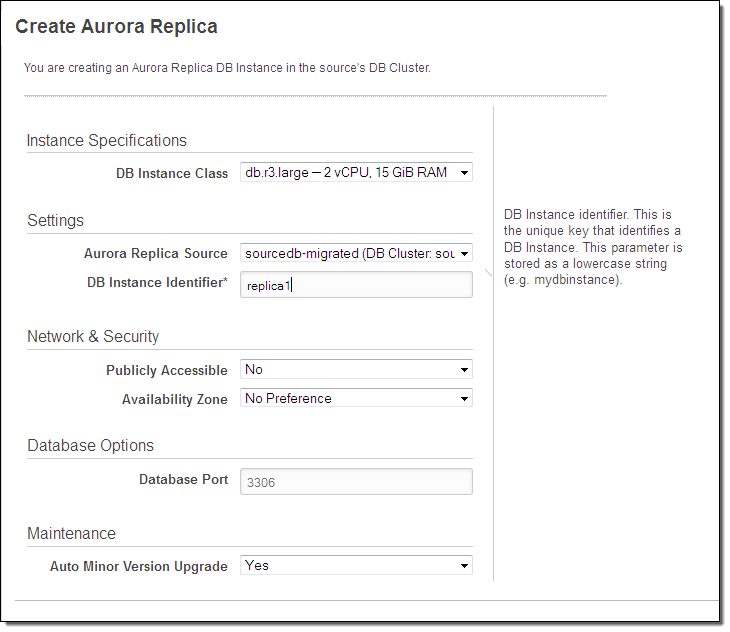
I would like to extend a warm welcome to the newest AWS Community Heroes:
- Adam Smolnik
- Kai Henry
- Onur Salk
- Paolo Latella
- Raphael Francis
- Rob Linton
The Heroes share their enthusiasm for AWS via social media, blogs, events, user groups, and workshops. Let’s take a look at their bios to learn more.
Adam Smolnik
 Adam is a Principal Software Engineer at Pitney Bowes, a global technology company offering products and solutions that enable commerce in the areas of customer information management, location intelligence, customer engagement, shipping and mailing, and global ecommerce. Prior to Pitney Bowes, Adam worked as an application developer, consultant, and designer for companies like Kroll Ontrack, IBM and EDS. He supports and publishes articles on Chmurowisko.pl, the most recognized Polish website revolving around Cloud technology and premier source of information about Amazon AWS and Cloud Computing in general.
Adam is a Principal Software Engineer at Pitney Bowes, a global technology company offering products and solutions that enable commerce in the areas of customer information management, location intelligence, customer engagement, shipping and mailing, and global ecommerce. Prior to Pitney Bowes, Adam worked as an application developer, consultant, and designer for companies like Kroll Ontrack, IBM and EDS. He supports and publishes articles on Chmurowisko.pl, the most recognized Polish website revolving around Cloud technology and premier source of information about Amazon AWS and Cloud Computing in general.
Adam is also a co-founder of AWS User Group Poland (established in 2014), an active speaker and trainer at Cloud conferences, instructor at Cloud and Software workshops as well as co-organizer of the Cloudyna conference. Be sure to take a look at his LinkedIn profile.
Kai Henry
 Kai Hendry is the founder of Webconverger, a company and open source project of the same name, supplier of Web kiosk and signage software since 2007. After graduating from the University of Helsinki with a Master’s degree in Computer Science in 2005, he travelled and worked around the world to discover insecure Web kiosks in Internet cafes and public spaces. On return to England, he engineered a secure Web kiosk operating system based on Debian and maintained it on weekends whilst in fulltime employment working upon Web technologies.
Kai Hendry is the founder of Webconverger, a company and open source project of the same name, supplier of Web kiosk and signage software since 2007. After graduating from the University of Helsinki with a Master’s degree in Computer Science in 2005, he travelled and worked around the world to discover insecure Web kiosks in Internet cafes and public spaces. On return to England, he engineered a secure Web kiosk operating system based on Debian and maintained it on weekends whilst in fulltime employment working upon Web technologies.
Over time, Webconverger’s popularity grew and by the end of his tenure in the telecommunication’s industry he decided move to Singapore, get married and focus on his company. Now a successful small business, Webconverger provides reliable management service for Web kiosks using AWS services such as S3 with Route 53 fail over.
Kai is an active member of the maker community in Singapore, usually found working from Hackerspace.SG, helps with the local AWS User Group Singapore Meetup group and organizes the Singapore Hack and Tell chapter.
You can find Kai on Twitter and at his home page.
Onur Salk
 For 8 years Onur Salk has been leading the infrastructure and technical operations of Yemeksepeti.com, which has since been acquired by Delivery Hero. He is also responsible for Foodonclick.com, Ifood.jo, Yemek.com and Irmik.com.
For 8 years Onur Salk has been leading the infrastructure and technical operations of Yemeksepeti.com, which has since been acquired by Delivery Hero. He is also responsible for Foodonclick.com, Ifood.jo, Yemek.com and Irmik.com.
He helped build Yemek.com, a fully automated and self-healing website, which runs entirely on Amazon Web Services. In a first for Turkey, he worked to migrate Foodonclick.com to AWS, achieving implementing of MS SQL Always On running in a production environment.
Onur regularly publishes AWS articles on his blog Wekanban.com and is the founder and organizer of the AWS User Group Turkey Meetup group in Istanbul. He is passionate about cloud computing, automation, configuration management and DevOps. He also enjoys programming in Python and developing open source AWS tools.
You can find Onur on Twitter, read his blog, and view his LinkedIn profile.
Paolo Latella
 Paolo Latella is a Cloud Solutions Architect and AWS Technical Trainer at XPeppers, an enterprise focused on Cloud technologies and DevOps methodologies and member of the AWS Partner Network (APN). Paolo has more than 15 years of experience in IT and has worked on AWS technologies since 2008. Before joining XPeppers he was a Solution Architect Team Leader at Interact, an enterprise leader in Digital Media for the Cloud. There he followed the first Hybrid Cloud project for the Italian Public Sector.
Paolo Latella is a Cloud Solutions Architect and AWS Technical Trainer at XPeppers, an enterprise focused on Cloud technologies and DevOps methodologies and member of the AWS Partner Network (APN). Paolo has more than 15 years of experience in IT and has worked on AWS technologies since 2008. Before joining XPeppers he was a Solution Architect Team Leader at Interact, an enterprise leader in Digital Media for the Cloud. There he followed the first Hybrid Cloud project for the Italian Public Sector.
He graduated from the University of Rome “La Sapienza” in Computer Science, publishing a thesis about “Auto configuration and monitoring of Wireless Sensors Network”. After graduating, he received a research grant for the study of advanced network systems and mission critical services at the CASPUR (Consorzio Applicazioni Supercalcolo per Università e Ricerca) now CINECA.
Paolo hosts regular meetings as the Co-Founder of AWS User Group Italia and AWS User Group Ticino. He can also be found participating at various technology conferences in Italy.
You can follow Paolo on Twitter, read his LinkedIn profile, or inspect his GitHub repos.
Raphael Francis
 Raphael Francis is a proud Cebuano technopreneur. He is the Chief Technology Officer of Upteam Corporation, a worldwide supplier of authentic, curated and pre-owned high-end brands. He serves as a consultant to the management services company Penbrothers, business SaaS company Yewusoftware and was a founding member of AVA.ph, the Philippine’s first curated marketplace for premium brands. He also served as the CTO of Techforge Solutions, an IT firm that launched various brands, enterprises and online ventures.
Raphael Francis is a proud Cebuano technopreneur. He is the Chief Technology Officer of Upteam Corporation, a worldwide supplier of authentic, curated and pre-owned high-end brands. He serves as a consultant to the management services company Penbrothers, business SaaS company Yewusoftware and was a founding member of AVA.ph, the Philippine’s first curated marketplace for premium brands. He also served as the CTO of Techforge Solutions, an IT firm that launched various brands, enterprises and online ventures.
“Sir Rafi” has genuine enthusiasm for effective mentoring. He comes from a family of teachers and educators, and was a professor himself at the Sacred Heart – Ateneo de Cebu and La Salle College of St. Benilde.
As co-leader of the AWS User Group Philippines since 2013, he regularly answers questions, gives advice and organizes events for the AWS community. Read Raphael’s LinkedIn profile to learn more.
Rob Linton
 Rob Linton is the founder of Podzy, an encrypted on premise replacement for Dropbox, which was the winner of the 2013 Australian iAwards Toolsets category. Over the past 20 years as a data specialist he’s worked as a spatial information systems professional and data professional. His first company, Logicaltech Systalk has received numerous awards and commendations for product excellence, and was the winner of the Australian 2010 iAwards.
Rob Linton is the founder of Podzy, an encrypted on premise replacement for Dropbox, which was the winner of the 2013 Australian iAwards Toolsets category. Over the past 20 years as a data specialist he’s worked as a spatial information systems professional and data professional. His first company, Logicaltech Systalk has received numerous awards and commendations for product excellence, and was the winner of the Australian 2010 iAwards.
In July 2011 he founded the first AWS User Group in Australia. He is a certified Security Systems ISO 27001 auditor, and one of the few people to receive a perfect score for his SQL Server certification. His last book was Amazon Web Services: Migrate your .NET Enterprise Application to the Amazon Cloud.
In his spare time he enjoys coding in C++ on his Macbook Pro and chasing his kids away from things that break relatively easily.
Welcome Aboard
Please join me in welcoming our newest heroes!
— Jeff;